[GitHub] [iceberg] Fokko merged pull request #6130: Build: Bump mkdocs from 1.4.1 to 1.4.2 in /python
Fokko merged PR #6130: URL: https://github.com/apache/iceberg/pull/6130 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6127: Python: Add expression evaluator
rdblue commented on code in PR #6127:
URL: https://github.com/apache/iceberg/pull/6127#discussion_r1014889665
##
python/tests/expressions/test_evaluator.py:
##
@@ -0,0 +1,203 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+from typing import Any, List, TypeVar
+
+from pyiceberg.expressions import AlwaysTrue, AlwaysFalse, LessThan,
Reference, LessThanOrEqual, GreaterThan, \
+GreaterThanOrEqual, EqualTo, NotEqualTo, IsNaN, NotNaN, IsNull, NotNull,
Not, And, Or, In, NotIn
+from pyiceberg.expressions.literals import literal
+from pyiceberg.expressions.visitors import evaluator
+from pyiceberg.files import StructProtocol
+from pyiceberg.schema import Schema
+from pyiceberg.types import NestedField, LongType, StringType, DoubleType
+
+V = TypeVar('V')
+
+
+class Column:
Review Comment:
I fixed this by adding decorators that will coerce arguments before passing
to the constructors of the frozen data classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6127: Python: Add expression evaluator
rdblue commented on code in PR #6127: URL: https://github.com/apache/iceberg/pull/6127#discussion_r1014890146 ## python/pyiceberg/expressions/__init__.py: ## @@ -281,6 +289,30 @@ def __invert__(self) -> BoundIsNull: return BoundIsNull(self.term) +def coerce_unary_arguments(data_class: Union[type, None]) -> Union[type, Callable[[type], type]]: Review Comment: @Fokko, this PR introduces 3 of these decorators to make it easy to construct predicates. This decorator replaces `__init__` with a version that converts a string passed as `term` into a `Reference`. This makes it much easier to create expressions, as you can see from the test cases. The other decorators handle set predicates and literal predicates. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6123: Python: Support creating a DateLiteral from a date (#6120)
rdblue commented on code in PR #6123: URL: https://github.com/apache/iceberg/pull/6123#discussion_r1014891415 ## python/pyiceberg/utils/datetime.py: ## @@ -47,11 +47,16 @@ def micros_to_time(micros: int) -> time: return time(hour=hours, minute=minutes, second=seconds, microsecond=microseconds) -def date_to_days(date_str: str) -> int: +def date_str_to_days(date_str: str) -> int: Review Comment: Does this need to be renamed? Why not support both with the same name to avoid a breaking change? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6118: Parquet, Core: Fix collection of Parquet metrics when column names co…
rdblue commented on PR #6118: URL: https://github.com/apache/iceberg/pull/6118#issuecomment-1304892034 @zhongyujiang can you explain the fix a bit more clearly? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6110: API: Hash floats -0.0 and 0.0 to the same bucket
rdblue merged PR #6110: URL: https://github.com/apache/iceberg/pull/6110 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6110: API: Hash floats -0.0 and 0.0 to the same bucket
rdblue commented on PR #6110: URL: https://github.com/apache/iceberg/pull/6110#issuecomment-1304892916 Thanks, @fb913bf0de288ba84fe98f7a23d35edfdb22381! Looks great. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6093: Spark-3.0: Remove/update spark-3.0 mention from Docs and Builds
rdblue commented on code in PR #6093: URL: https://github.com/apache/iceberg/pull/6093#discussion_r1014892191 ## docs/aws.md: ## @@ -488,7 +488,7 @@ disaster recovery, etc. For using cross-region access points, we need to additionally set `use-arn-region-enabled` catalog property to `true` to enable `S3FileIO` to make cross-region calls, it's not required for same / multi-region access points. -For example, to use S3 access-point with Spark 3.0, you can start the Spark SQL shell with: +For example, to use S3 access-point with Spark 3.3, you can start the Spark SQL shell with: Review Comment: What about using 3.x? Or maybe just omit the version number? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6093: Spark-3.0: Remove/update spark-3.0 mention from Docs and Builds
rdblue merged PR #6093: URL: https://github.com/apache/iceberg/pull/6093 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6094: Spark-3.0: Remove spark/v3.0 folder
rdblue commented on PR #6094: URL: https://github.com/apache/iceberg/pull/6094#issuecomment-1304894017 @ajantha-bhat, I merged #6093. Can you rebase this one? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6108: SparkBatchQueryScan logs too much - #6106
rdblue commented on PR #6108: URL: https://github.com/apache/iceberg/pull/6108#issuecomment-1304894200 Running CI again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6076: Python: Replace mmh3 with mmhash3
rdblue merged PR #6076: URL: https://github.com/apache/iceberg/pull/6076 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6076: Python: Replace mmh3 with mmhash3
rdblue commented on PR #6076: URL: https://github.com/apache/iceberg/pull/6076#issuecomment-1304894694 Thanks, @Fokko! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6064: Support 2-level list and maps type in RemoveIds.
rdblue commented on PR #6064: URL: https://github.com/apache/iceberg/pull/6064#issuecomment-1304895348 Looks good to me. Merged. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6064: Support 2-level list and maps type in RemoveIds.
rdblue merged PR #6064: URL: https://github.com/apache/iceberg/pull/6064 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6065: Fix TestAggregateBinding
rdblue merged PR #6065: URL: https://github.com/apache/iceberg/pull/6065 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6065: Fix TestAggregateBinding
rdblue commented on PR #6065: URL: https://github.com/apache/iceberg/pull/6065#issuecomment-1304895651 Thanks, @huaxingao! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6058: Core,Spark: Add metadata to Scan Report
rdblue commented on code in PR #6058:
URL: https://github.com/apache/iceberg/pull/6058#discussion_r1014893653
##
core/src/main/java/org/apache/iceberg/BaseTableScan.java:
##
@@ -141,6 +142,8 @@ public CloseableIterable planFiles() {
doPlanFiles(),
() -> {
planningDuration.stop();
+Map metadata =
Maps.newHashMap(context().options());
+metadata.putAll(EnvironmentContext.get());
Review Comment:
How is it helpful? I see that metadata is generic, but I don't understand
the value of mixing these together, versus having a separate context map and
options map.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6058: Core,Spark: Add metadata to Scan Report
rdblue commented on code in PR #6058:
URL: https://github.com/apache/iceberg/pull/6058#discussion_r1014893913
##
core/src/main/java/org/apache/iceberg/EnvironmentContext.java:
##
@@ -0,0 +1,75 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg;
+
+import java.util.Map;
+import java.util.function.Supplier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+
+public class EnvironmentContext {
+ public static final String ENGINE_NAME = "engine-name";
+ public static final String ENGINE_VERSION = "engine-version";
+
+ private EnvironmentContext() {}
+
+ private static final Map PROPERTIES =
Maps.newConcurrentMap();
+ private static final ThreadLocal>>
THREAD_LOCAL_PROPERTIES =
+ ThreadLocal.withInitial(Maps::newConcurrentMap);
Review Comment:
Why put these inside a `ThreadLocal`? Then these need to be defined for
every thread. Instead, you could use the fact that the `Supplier` should return
the correct value for any thread and just use a simple map.
Using a `Supplier` makes it so someone else has to handle the `ThreadLocal`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6056: Parquet: Remove the row position since parquet row group has it natively
rdblue commented on PR #6056: URL: https://github.com/apache/iceberg/pull/6056#issuecomment-1304896473 Do we trust this value from Parquet? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014894248
##
core/src/main/java/org/apache/iceberg/rest/CatalogHandlers.java:
##
@@ -222,13 +222,27 @@ public static LoadTableResponse createTable(
throw new IllegalStateException("Cannot wrap catalog that does not produce
BaseTable");
}
+ /**
+ * @param catalog The catalog instance
+ * @param ident The table identifier of the table to be dropped.
+ * @deprecated Will be removed in 1.2.0, use {@link
CatalogHandlers#dropTable(Catalog,
+ * TableIdentifier, boolean)}.
+ */
+ @Deprecated
Review Comment:
Rather than adding a boolean option, can we have two methods, `dropTable`
and `purgeTable`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014894712
##
core/src/test/java/org/apache/iceberg/catalog/CatalogTests.java:
##
@@ -799,6 +799,23 @@ public void testDropTable() {
Assert.assertFalse("Table should not exist after drop",
catalog.tableExists(TABLE));
}
+ @Test
+ public void testDropTableWithPurge() {
+C catalog = catalog();
+
+if (requiresNamespaceCreate()) {
+ catalog.createNamespace(NS);
+}
+
+Assertions.assertThat(catalog.tableExists(TABLE)).isFalse();
+
+catalog.buildTable(TABLE, SCHEMA).create();
+Assertions.assertThat(catalog.tableExists(TABLE)).isTrue();
+
+Assertions.assertThat(catalog.dropTable(TABLE, true)).isTrue();
+Assertions.assertThat(catalog.tableExists(TABLE)).isFalse();
Review Comment:
This looks copied from the test above. Can you copy the assertions with
context strings?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014894879
##
core/src/test/java/org/apache/iceberg/rest/RESTCatalogAdapter.java:
##
@@ -320,7 +321,10 @@ public T handleRequest(
case DROP_TABLE:
{
- CatalogHandlers.dropTable(catalog, identFromPathVars(vars));
+ CatalogHandlers.dropTable(
+ catalog,
+ identFromPathVars(vars),
+ PropertyUtil.propertyAsBoolean(vars, "purgeRequested", false));
Review Comment:
You mean always using `purge=true`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073: URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014894952 ## core/src/test/java/org/apache/iceberg/rest/TestHTTPClient.java: ## @@ -219,7 +219,7 @@ private static Item doExecuteRequest( restClient.head(path, headers, onError); return null; case DELETE: -return restClient.delete(path, Item.class, headers, onError); +return restClient.delete(path, Item.class, () -> headers, onError); Review Comment: Look good to me. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014895276
##
core/src/main/java/org/apache/iceberg/rest/CatalogHandlers.java:
##
@@ -222,8 +222,8 @@ public static LoadTableResponse createTable(
throw new IllegalStateException("Cannot wrap catalog that does not produce
BaseTable");
}
- public static void dropTable(Catalog catalog, TableIdentifier ident) {
-boolean dropped = catalog.dropTable(ident);
+ public static void dropTable(Catalog catalog, TableIdentifier ident, boolean
purge) {
+boolean dropped = catalog.dropTable(ident, purge);
Review Comment:
The `SessionCatalog` API requires specifying purge. But the `RESTCatalog`
adapter does call `Catalog.dropTable` to have the same behavior.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
rdblue commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1014895355
##
core/src/test/java/org/apache/iceberg/rest/RESTCatalogAdapter.java:
##
@@ -320,7 +321,10 @@ public T handleRequest(
case DROP_TABLE:
{
- CatalogHandlers.dropTable(catalog, identFromPathVars(vars));
+ CatalogHandlers.dropTable(
+ catalog,
+ identFromPathVars(vars),
+ PropertyUtil.propertyAsBoolean(vars, "purgeRequested", false));
Review Comment:
I think this is correct for the REST API. If `purgeRequested` was not set
then it was not requested. This should be consistent behavior, since purge
would cause a failure before.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014895768 ## python/pyiceberg/expressions/visitors.py: ## @@ -517,7 +519,7 @@ def visit_equal(self, term: BoundTerm, literal: Literal[Any]) -> bool: pos = term.ref().accessor.position field = self.partition_fields[pos] -if field.lower_bound is None: +if field.lower_bound is None or field.upper_bound is None: Review Comment: If one is `None` then both should be, so this shouldn't have any effect. But it's fine to update this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014895867 ## python/pyiceberg/expressions/visitors.py: ## @@ -526,7 +528,7 @@ def visit_equal(self, term: BoundTerm, literal: Literal[Any]) -> bool: if lower > literal.value: return ROWS_CANNOT_MATCH -upper = _from_byte_buffer(term.ref().field.field_type, field.lower_bound) +upper = _from_byte_buffer(term.ref().field.field_type, field.upper_bound) Review Comment: @Fokko, can you check why tests didn't catch this case? We should ensure this is tested properly and separate the fix into its own PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ddrinka commented on a diff in pull request #6123: Python: Support creating a DateLiteral from a date (#6120)
ddrinka commented on code in PR #6123: URL: https://github.com/apache/iceberg/pull/6123#discussion_r1014897183 ## python/pyiceberg/utils/datetime.py: ## @@ -47,11 +47,16 @@ def micros_to_time(micros: int) -> time: return time(hour=hours, minute=minutes, second=seconds, microsecond=microseconds) -def date_to_days(date_str: str) -> int: +def date_str_to_days(date_str: str) -> int: Review Comment: My thought process was that this API is still pre 1.0 and the existing name was misleading, so better to improve it now. I have no preference either way though, so happy to adjust. I'm not sure how to support both with the same name though? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] jzhuge commented on a diff in pull request #4925: API: Add view interfaces
jzhuge commented on code in PR #4925:
URL: https://github.com/apache/iceberg/pull/4925#discussion_r1014897964
##
api/src/main/java/org/apache/iceberg/view/ViewBuilder.java:
##
@@ -0,0 +1,144 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.catalog.ViewCatalog;
+
+/**
+ * A builder used to create or replace a SQL {@link View}.
+ *
+ * Call {@link ViewCatalog#buildView} to create a new builder.
+ */
+public interface ViewBuilder {
+ /**
+ * Set the view schema.
+ *
+ * @param schema view schema
+ * @return this for method chaining
+ */
+ ViewBuilder withSchema(Schema schema);
+
+ /**
+ * Set the view query.
+ *
+ * @param query view query
+ * @return this for method chaining
+ */
+ ViewBuilder withQuery(String query);
+
+ /**
+ * Set the view SQL dialect.
+ *
+ * @param dialect view SQL dialect
+ * @return this for method chaining
+ */
+ ViewBuilder withDialect(String dialect);
+
+ /**
+ * Set the view default catalog.
+ *
+ * @param defaultCatalog view default catalog
+ * @return this for method chaining
+ */
+ ViewBuilder withDefaultCatalog(String defaultCatalog);
+
+ /**
+ * Set the view default namespaces.
+ *
+ * @param defaultNamespaces view default namespaces
+ * @return this for method chaining
+ */
+ ViewBuilder withDefaultNamespace(List defaultNamespaces);
Review Comment:
Changed to use Namespace class and use singular
##
api/src/main/java/org/apache/iceberg/view/SQLViewRepresentation.java:
##
@@ -0,0 +1,41 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+
+public interface SQLViewRepresentation extends ViewRepresentation {
+
+ @Override
+ default Type type() {
+return Type.SQL;
+ }
+
+ String query();
+
+ String dialect();
+
+ String defaultCatalog();
+
+ List defaultNamespace();
Review Comment:
Changed to use Namespace class and use singular
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] jzhuge commented on a diff in pull request #4925: API: Add view interfaces
jzhuge commented on code in PR #4925:
URL: https://github.com/apache/iceberg/pull/4925#discussion_r1014898267
##
api/src/main/java/org/apache/iceberg/view/ViewBuilder.java:
##
@@ -0,0 +1,144 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.catalog.ViewCatalog;
+
+/**
+ * A builder used to create or replace a SQL {@link View}.
+ *
+ * Call {@link ViewCatalog#buildView} to create a new builder.
+ */
+public interface ViewBuilder {
+ /**
+ * Set the view schema.
+ *
+ * @param schema view schema
+ * @return this for method chaining
+ */
+ ViewBuilder withSchema(Schema schema);
+
+ /**
+ * Set the view query.
+ *
+ * @param query view query
+ * @return this for method chaining
+ */
+ ViewBuilder withQuery(String query);
+
+ /**
+ * Set the view SQL dialect.
+ *
+ * @param dialect view SQL dialect
+ * @return this for method chaining
+ */
+ ViewBuilder withDialect(String dialect);
+
+ /**
+ * Set the view default catalog.
+ *
+ * @param defaultCatalog view default catalog
+ * @return this for method chaining
+ */
+ ViewBuilder withDefaultCatalog(String defaultCatalog);
+
+ /**
+ * Set the view default namespaces.
+ *
+ * @param defaultNamespaces view default namespaces
+ * @return this for method chaining
+ */
+ ViewBuilder withDefaultNamespace(List defaultNamespaces);
+
+ /**
+ * Set the view field aliases.
+ *
+ * @param fieldAliases view field aliases
+ * @return this for method chaining
+ */
+ ViewBuilder withFieldAliases(List fieldAliases);
+
+ /**
+ * Set the view field comments.
+ *
+ * @param fieldComments view field comments
+ * @return this for method chaining
+ */
+ ViewBuilder withFieldComments(List fieldComments);
+
+ /**
+ * Add key/value properties to the view.
+ *
+ * @param properties key/value properties
+ * @return this for method chaining
+ */
+ ViewBuilder withProperties(Map properties);
+
+ /**
+ * Add a key/value property to the view.
+ *
+ * @param key a key
+ * @param value a value
+ * @return this for method chaining
+ */
+ ViewBuilder withProperty(String key, String value);
+
+ /**
+ * Set a location for the view.
+ *
+ * @param location a location
+ * @return this for method chaining
+ */
+ ViewBuilder withLocation(String location);
+
+ /**
+ * Add a SQL {@link View} for a different dialect.
+ *
+ * If its dialect is the same as the SQL view being built, {@link
IllegalArgumentException}
Review Comment:
Fixed
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4925: API: Add view interfaces
stevenzwu commented on code in PR #4925:
URL: https://github.com/apache/iceberg/pull/4925#discussion_r1014899332
##
api/src/main/java/org/apache/iceberg/view/SQLViewRepresentation.java:
##
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+import org.apache.iceberg.catalog.Namespace;
+
+public interface SQLViewRepresentation extends ViewRepresentation {
+
+ @Override
+ default Type type() {
+return Type.SQL;
+ }
+
+ /** The view query SQL text. */
+ String query();
+
+ /** The view query SQL dialect. */
+ String dialect();
+
+ /** The default catalog when the view is created. */
+ String defaultCatalog();
Review Comment:
this is a getter. wondering why `default...`? should it just be `catalog()`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4925: API: Add view interfaces
stevenzwu commented on code in PR #4925:
URL: https://github.com/apache/iceberg/pull/4925#discussion_r1014899413
##
api/src/main/java/org/apache/iceberg/view/SQLViewRepresentation.java:
##
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+import org.apache.iceberg.catalog.Namespace;
+
+public interface SQLViewRepresentation extends ViewRepresentation {
+
+ @Override
+ default Type type() {
+return Type.SQL;
+ }
+
+ /** The view query SQL text. */
+ String query();
+
+ /** The view query SQL dialect. */
+ String dialect();
+
+ /** The default catalog when the view is created. */
+ String defaultCatalog();
+
+ /** The default namespace when the view is created. */
+ Namespace defaultNamespace();
Review Comment:
similar question, should this just be `namespace()`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] jzhuge commented on a diff in pull request #4925: API: Add view interfaces
jzhuge commented on code in PR #4925:
URL: https://github.com/apache/iceberg/pull/4925#discussion_r1014903529
##
api/src/main/java/org/apache/iceberg/view/SQLViewRepresentation.java:
##
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.view;
+
+import java.util.List;
+import org.apache.iceberg.catalog.Namespace;
+
+public interface SQLViewRepresentation extends ViewRepresentation {
+
+ @Override
+ default Type type() {
+return Type.SQL;
+ }
+
+ /** The view query SQL text. */
+ String query();
+
+ /** The view query SQL dialect. */
+ String dialect();
+
+ /** The default catalog when the view is created. */
+ String defaultCatalog();
Review Comment:
In a Spark/Presto SQL session, you can run `USE` to set default catalog and
namespace, thus the "default".
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014903669 ## python/tests/table/test_scan.py: ## @@ -0,0 +1,177 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +# pylint:disable=redefined-outer-name +import glob +import json +import os +import tempfile +from typing import Tuple + +import pytest +from fastavro import reader, writer + +from pyiceberg.expressions import ( +BooleanExpression, +EqualTo, +IsNull, +Reference, +) +from pyiceberg.expressions.literals import literal +from pyiceberg.serializers import FromInputFile +from pyiceberg.table import Table +from tests.conftest import LocalFileIO +from tests.io.test_io import LocalInputFile + + +@pytest.fixture +def temperatures_table() -> Table: Review Comment: Yes, this should generate a sample table rather than putting binaries in the repo. Initially, we can build all of this based on just Avro and add Parquet tests later. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014903835 ## python/pyiceberg/table/scan.py: ## @@ -0,0 +1,103 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +import itertools +from abc import ABC, abstractmethod +from typing import Iterable, List, Optional + +from pydantic import Field + +from pyiceberg.expressions import AlwaysTrue, BooleanExpression +from pyiceberg.expressions.visitors import manifest_evaluator +from pyiceberg.io import FileIO +from pyiceberg.manifest import DataFile, ManifestFile +from pyiceberg.table import PartitionSpec, Snapshot, Table +from pyiceberg.utils.iceberg_base_model import IcebergBaseModel + +ALWAYS_TRUE = AlwaysTrue() + + +class FileScanTask(IcebergBaseModel): +"""A scan task over a range of bytes in a single data file.""" + +manifest: ManifestFile = Field() +data_file: DataFile = Field() +_residual: BooleanExpression = Field() +spec: PartitionSpec = Field() +start: int = Field(default=0) + +@property +def length(self) -> int: +return self.data_file.file_size_in_bytes + + +class TableScan(ABC): Review Comment: Why does this API not match the Java API? Is there something more pythonic about this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014903928 ## python/pyiceberg/table/scan.py: ## @@ -0,0 +1,103 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +import itertools +from abc import ABC, abstractmethod +from typing import Iterable, List, Optional + +from pydantic import Field + +from pyiceberg.expressions import AlwaysTrue, BooleanExpression +from pyiceberg.expressions.visitors import manifest_evaluator +from pyiceberg.io import FileIO +from pyiceberg.manifest import DataFile, ManifestFile +from pyiceberg.table import PartitionSpec, Snapshot, Table +from pyiceberg.utils.iceberg_base_model import IcebergBaseModel + +ALWAYS_TRUE = AlwaysTrue() Review Comment: I'd prefer not adding these constants everywhere. Just use `AlwaysTrue()` in place of this. It's a singleton. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on code in PR #6069:
URL: https://github.com/apache/iceberg/pull/6069#discussion_r1014904027
##
python/pyiceberg/table/scan.py:
##
@@ -0,0 +1,103 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import itertools
+from abc import ABC, abstractmethod
+from typing import Iterable, List, Optional
+
+from pydantic import Field
+
+from pyiceberg.expressions import AlwaysTrue, BooleanExpression
+from pyiceberg.expressions.visitors import manifest_evaluator
+from pyiceberg.io import FileIO
+from pyiceberg.manifest import DataFile, ManifestFile
+from pyiceberg.table import PartitionSpec, Snapshot, Table
+from pyiceberg.utils.iceberg_base_model import IcebergBaseModel
+
+ALWAYS_TRUE = AlwaysTrue()
+
+
+class FileScanTask(IcebergBaseModel):
+"""A scan task over a range of bytes in a single data file."""
+
+manifest: ManifestFile = Field()
+data_file: DataFile = Field()
+_residual: BooleanExpression = Field()
+spec: PartitionSpec = Field()
+start: int = Field(default=0)
+
+@property
+def length(self) -> int:
+return self.data_file.file_size_in_bytes
+
+
+class TableScan(ABC):
+"""API for configuring a table scan."""
+
+table: Table
+snapshot: Snapshot
+expression: BooleanExpression
+
+def __init__(self, table: Table, snapshot: Optional[Snapshot] = None,
expression: BooleanExpression = ALWAYS_TRUE):
+self.table = table
+self.expression = expression or ALWAYS_TRUE
+if resolved_snapshot := snapshot or table.current_snapshot():
+self.snapshot = resolved_snapshot
+else:
+raise ValueError("Unable to resolve to a Snapshot to use for the
table scan.")
+
+@abstractmethod
+def plan_files(self) -> Iterable[FileScanTask]:
Review Comment:
In Java, there are several different types of tasks. I'd recommend using the
same pattern and not requiring this to be `FileScanTask`. Introduce an abstract
`ScanTask` and return an iterable of that instead.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] huaxingao commented on pull request #6065: Fix TestAggregateBinding
huaxingao commented on PR #6065: URL: https://github.com/apache/iceberg/pull/6065#issuecomment-1304926068 Thanks! @rdblue @nastra @Fokko -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue opened a new pull request, #6131: Python: Add initial TableScan implementation
rdblue opened a new pull request, #6131:
URL: https://github.com/apache/iceberg/pull/6131
This adds an implementation of `TableScan` that is an alternative to the one
in #6069. This doesn't implement `plan_files`, it is just to demonstrate a
possible scan API.
This scan API works like the Java scan API, but also allows passing scan
options when creating an initial scan. Both of these are supported:
```python
scan = table.scan(
row_filter=In("id", [5, 6, 7]),
selected_fields=("id", "data"),
snapshot_id=1234567890
)
# OR
scan = table.scan() \
.filter_rows(In("id", [5, 6, 7]))
.select("id", "data")
.use_snapshot(1234567890)
```
I think this is a reasonable way to get more pythonic (by passing optional
arguments) and also mostly match the API and behavior in the JVM implementation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
rdblue commented on PR #6069: URL: https://github.com/apache/iceberg/pull/6069#issuecomment-1304927324 @Fokko, @dhruv-pratap, I posted an alternative scan API in a draft as #6131. Please take a look. That behaves like this one and allows you to specify optional arguments when creating a scan, but also allows the same syntax that Java uses. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6131: Python: Add initial TableScan implementation
rdblue commented on code in PR #6131: URL: https://github.com/apache/iceberg/pull/6131#discussion_r1014914176 ## python/pyiceberg/table/__init__.py: ## @@ -14,30 +14,43 @@ # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License. - - -from typing import Dict, List, Optional - -from pydantic import Field - +from typing import ( +ClassVar, +Dict, +List, +Optional, +) + +from pyiceberg.expressions import AlwaysTrue, And, BooleanExpression from pyiceberg.schema import Schema from pyiceberg.table.metadata import TableMetadata from pyiceberg.table.partitioning import PartitionSpec from pyiceberg.table.snapshots import Snapshot, SnapshotLogEntry from pyiceberg.table.sorting import SortOrder -from pyiceberg.typedef import Identifier -from pyiceberg.utils.iceberg_base_model import IcebergBaseModel +from pyiceberg.typedef import EMPTY_DICT, Identifier, Properties + +class Table: Review Comment: @Fokko, I removed Pydantic from this because it was conflicting with the `schema` method. I think we should probably make these changes to the `Table` class either way. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6131: Python: Add initial TableScan implementation
rdblue commented on code in PR #6131: URL: https://github.com/apache/iceberg/pull/6131#discussion_r1014914272 ## python/pyiceberg/table/__init__.py: ## @@ -90,3 +103,90 @@ def snapshot_by_name(self, name: str) -> Optional[Snapshot]: def history(self) -> List[SnapshotLogEntry]: """Get the snapshot history of this table.""" return self.metadata.snapshot_log + + +class TableScan: +_always_true: ClassVar[BooleanExpression] = AlwaysTrue() Review Comment: This was needed to avoid calling functions in arg defaults. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014915514 ## python/pyiceberg/expressions/__init__.py: ## @@ -68,7 +72,6 @@ def eval(self, struct: StructProtocol) -> T: # pylint: disable=W0613 """Returns the value at the referenced field's position in an object that abides by the StructProtocol""" -@dataclass(frozen=True) Review Comment: Why are the changes to these classes necessary? I'd prefer to keep these as frozen data classes if possible. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014915923 ## python/pyiceberg/expressions/literals.py: ## @@ -213,6 +217,26 @@ class LongLiteral(Literal[int]): def __init__(self, value: int): super().__init__(value, int) +def __add__(self, other: Any) -> LongLiteral: Review Comment: What about `increment` and `decrement` methods since we only need to add or subtract 1? I think I like the idea of implementing this on the literal. The main issue that I have with this is that it modifies the value of the literal. I think introducing mutability is going to cause problems because this will modify the original expression when we project, which should not happen. (That may also be why expressions are no longer immutable?) I think this should just return a new literal rather than `self`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014916040 ## python/pyiceberg/transforms.py: ## @@ -173,6 +201,23 @@ def apply(self, value: Optional[S]) -> Optional[int]: def result_type(self, source: IcebergType) -> IcebergType: return IntegerType() +def project(self, name: str, pred: BoundPredicate) -> Optional[UnboundPredicate]: +func = self.transform(pred.term.ref().field.field_type) Review Comment: Is there a better name than `func`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014916582 ## python/pyiceberg/transforms.py: ## @@ -427,6 +486,20 @@ def can_transform(self, source: IcebergType) -> bool: TimestamptzType, } +def project(self, name: str, pred: BoundPredicate) -> Optional[UnboundPredicate]: Review Comment: Is this different than the other `DatesTransform` implementation? I might be missing it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014917102 ## python/pyiceberg/transforms.py: ## @@ -249,6 +294,20 @@ def satisfies_order_of(self, other: Transform) -> bool: def result_type(self, source: IcebergType) -> IcebergType: return IntegerType() +def project(self, name: str, pred: BoundPredicate) -> Optional[UnboundPredicate]: Review Comment: I think the date/time transforms need to use the same truncation logic as the `truncate` function. That's because the operation may need to change. For example: `ts < '2022-11-06T15:56'` with a `day` transform should be `ts_day <= '2022-11-06'`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6128: Python: Projection
rdblue commented on code in PR #6128:
URL: https://github.com/apache/iceberg/pull/6128#discussion_r1014917239
##
python/tests/expressions/test_expressions.py:
##
@@ -269,23 +283,23 @@ def test_bind_not_in_equal_term(table_schema_simple:
Schema):
def test_in_empty():
-assert In(Reference("foo"), ()) == AlwaysFalse()
+assert In(Reference("foo"), set()) == AlwaysFalse()
Review Comment:
I simplified unbound expression creation in a recent PR. That might help
here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6128: Python: Projection
rdblue commented on PR #6128: URL: https://github.com/apache/iceberg/pull/6128#issuecomment-1304935137 This is looking great. There are just two issues: 1. The date/time transforms should use the same logic as truncate for numbers since they're basically truncating 2. I don't think that the changes to expressions are necessary Thanks, @Fokko! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6128: Python: Projection
rdblue commented on PR #6128: URL: https://github.com/apache/iceberg/pull/6128#issuecomment-1304935954 > Removes the dataclasses from the expressions I hit the same issue in #6127 and fixed it a different way. We should talk about how to do this separately, but I think my update might be a reasonable fix. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6108: SparkBatchQueryScan logs too much - #6106
rdblue merged PR #6108: URL: https://github.com/apache/iceberg/pull/6108 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue closed issue #6106: SparkBatchQueryScan logs too much
rdblue closed issue #6106: SparkBatchQueryScan logs too much URL: https://github.com/apache/iceberg/issues/6106 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6108: SparkBatchQueryScan logs too much - #6106
rdblue commented on PR #6108: URL: https://github.com/apache/iceberg/pull/6108#issuecomment-1304936852 Thanks, @Omega359! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] github-actions[bot] closed issue #3825: Need an exmple of java code that uses hive as meta store and s3.
github-actions[bot] closed issue #3825: Need an exmple of java code that uses hive as meta store and s3. URL: https://github.com/apache/iceberg/issues/3825 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] github-actions[bot] commented on issue #3788: flink iceberg catalog support hadoop-conf-dir option to read hadoop conf?
github-actions[bot] commented on issue #3788: URL: https://github.com/apache/iceberg/issues/3788#issuecomment-1304938610 This issue has been closed because it has not received any activity in the last 14 days since being marked as 'stale' -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] github-actions[bot] closed issue #3788: flink iceberg catalog support hadoop-conf-dir option to read hadoop conf?
github-actions[bot] closed issue #3788: flink iceberg catalog support hadoop-conf-dir option to read hadoop conf? URL: https://github.com/apache/iceberg/issues/3788 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] github-actions[bot] commented on issue #3825: Need an exmple of java code that uses hive as meta store and s3.
github-actions[bot] commented on issue #3825: URL: https://github.com/apache/iceberg/issues/3825#issuecomment-1304938592 This issue has been closed because it has not received any activity in the last 14 days since being marked as 'stale' -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6123: Python: Support creating a DateLiteral from a date (#6120)
rdblue commented on code in PR #6123: URL: https://github.com/apache/iceberg/pull/6123#discussion_r1014922674 ## python/pyiceberg/utils/datetime.py: ## @@ -47,11 +47,16 @@ def micros_to_time(micros: int) -> time: return time(hour=hours, minute=minutes, second=seconds, microsecond=microseconds) -def date_to_days(date_str: str) -> int: +def date_str_to_days(date_str: str) -> int: Review Comment: Yeah, it probably isn't used anywhere. You're right: better to clean it up. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue closed issue #6120: [Python] The structure of a partition definition and partition instance should be consistent
rdblue closed issue #6120: [Python] The structure of a partition definition and partition instance should be consistent URL: https://github.com/apache/iceberg/issues/6120 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6123: Python: Support creating a DateLiteral from a date (#6120)
rdblue merged PR #6123: URL: https://github.com/apache/iceberg/pull/6123 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6123: Python: Support creating a DateLiteral from a date (#6120)
rdblue commented on PR #6123: URL: https://github.com/apache/iceberg/pull/6123#issuecomment-1304946218 Thanks, @ddrinka! I merged this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6117: Fix typo in `_ManifestEvalVisitor.visit_equal`
rdblue commented on PR #6117: URL: https://github.com/apache/iceberg/pull/6117#issuecomment-1304947082 I reopened this because I think it's a good idea to get it in independently. Thanks for finding this, @ddrinka! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #5150: Spark Integration to read from Snapshot ref
rdblue commented on PR #5150: URL: https://github.com/apache/iceberg/pull/5150#issuecomment-1304951287 > I am unsure of how to proceed for branches and tags usecase. Just making changes to read from branch/tag in SparkScanBuilder worked before for previous versions of spark - 3.1, 3.2. But for 3.3 , properties get overridden in SparkCatalog.java before reaching SparkScanBuilder.java The current implementation looks fine to me. If those code paths are taken, it indicates that Spark was passed syntax like `TIMESTAMP AS OF '...'`, which should be incompatible with `branch` or `tag` options. This PR already implements that because the snapshot passed to `SparkTable` is added to options. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #5150: Spark Integration to read from Snapshot ref
rdblue commented on PR #5150: URL: https://github.com/apache/iceberg/pull/5150#issuecomment-1304951951 This looks good to me. I'm rerunning CI since the failures don't look related to this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6017: Core, API: Field metadata support
rdblue commented on PR #6017: URL: https://github.com/apache/iceberg/pull/6017#issuecomment-1304952593 Closing this since there is discussion on the issue about whether it should be done. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue closed pull request #6017: Core, API: Field metadata support
rdblue closed pull request #6017: Core, API: Field metadata support URL: https://github.com/apache/iceberg/pull/6017 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #5984: Core, API: Support incremental scanning with branch
rdblue commented on code in PR #5984:
URL: https://github.com/apache/iceberg/pull/5984#discussion_r1014926208
##
api/src/main/java/org/apache/iceberg/IncrementalScan.java:
##
@@ -21,6 +21,23 @@
/** API for configuring an incremental scan. */
public interface IncrementalScan>
extends Scan {
+
+ /**
+ * Instructs this scan to look for changes starting from a particular
snapshot (inclusive).
+ *
+ * If the start snapshot is not configured, it is defaulted to the oldest
ancestor of the end
+ * snapshot (inclusive).
+ *
+ * @param fromSnapshotId the start snapshot ID (inclusive)
+ * @param referenceName the ref used
+ * @return this for method chaining
+ * @throws IllegalArgumentException if the start snapshot is not an ancestor
of the end snapshot
+ */
+ default ThisT fromSnapshotInclusive(long fromSnapshotId, String
referenceName) {
Review Comment:
@nastra, the distinction between a branch and a tag here is that a tag does
not change. It doesn't make sense to read incremental changes from a tag
because it is a fixed point in time.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #5984: Core, API: Support incremental scanning with branch
rdblue commented on code in PR #5984:
URL: https://github.com/apache/iceberg/pull/5984#discussion_r1014926208
##
api/src/main/java/org/apache/iceberg/IncrementalScan.java:
##
@@ -21,6 +21,23 @@
/** API for configuring an incremental scan. */
public interface IncrementalScan>
extends Scan {
+
+ /**
+ * Instructs this scan to look for changes starting from a particular
snapshot (inclusive).
+ *
+ * If the start snapshot is not configured, it is defaulted to the oldest
ancestor of the end
+ * snapshot (inclusive).
+ *
+ * @param fromSnapshotId the start snapshot ID (inclusive)
+ * @param referenceName the ref used
+ * @return this for method chaining
+ * @throws IllegalArgumentException if the start snapshot is not an ancestor
of the end snapshot
+ */
+ default ThisT fromSnapshotInclusive(long fromSnapshotId, String
referenceName) {
Review Comment:
@nastra, the distinction between a branch and a tag here is that a tag does
not change. It doesn't make sense to read incremental changes from a tag
because it is a fixed point in time. So I think it's okay to use `toBranch`
instead of `toRef`, although I'm not sure it's actually worth the distinction
since the other API uses `ref`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] lvyanquan commented on a diff in pull request #6111: Flink: Add 'cache.expiration-interval-ms' option to FlinkCatalog
lvyanquan commented on code in PR #6111:
URL: https://github.com/apache/iceberg/pull/6111#discussion_r1014937530
##
flink/v1.14/flink/src/main/java/org/apache/iceberg/flink/FlinkCatalogFactory.java:
##
@@ -145,8 +145,27 @@ protected Catalog createCatalog(
baseNamespace =
Namespace.of(properties.get(BASE_NAMESPACE).split("\\."));
}
-boolean cacheEnabled =
Boolean.parseBoolean(properties.getOrDefault(CACHE_ENABLED, "true"));
-return new FlinkCatalog(name, defaultDatabase, baseNamespace,
catalogLoader, cacheEnabled);
+boolean cacheEnabled = CatalogProperties.CACHE_ENABLED_DEFAULT;
Review Comment:
address it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ajantha-bhat commented on pull request #6094: Spark-3.0: Remove spark/v3.0 folder
ajantha-bhat commented on PR #6094: URL: https://github.com/apache/iceberg/pull/6094#issuecomment-1304974804 @rdblue: I have rebased this PR now. Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] lvyanquan commented on a diff in pull request #6111: Flink: Add 'cache.expiration-interval-ms' option to FlinkCatalog
lvyanquan commented on code in PR #6111:
URL: https://github.com/apache/iceberg/pull/6111#discussion_r1014938540
##
flink/v1.14/flink/src/main/java/org/apache/iceberg/flink/FlinkCatalogFactory.java:
##
@@ -145,8 +145,27 @@ protected Catalog createCatalog(
baseNamespace =
Namespace.of(properties.get(BASE_NAMESPACE).split("\\."));
}
-boolean cacheEnabled =
Boolean.parseBoolean(properties.getOrDefault(CACHE_ENABLED, "true"));
-return new FlinkCatalog(name, defaultDatabase, baseNamespace,
catalogLoader, cacheEnabled);
+boolean cacheEnabled = CatalogProperties.CACHE_ENABLED_DEFAULT;
+if (properties.containsKey(CatalogProperties.CACHE_ENABLED)) {
+ cacheEnabled =
Boolean.parseBoolean(properties.get(CatalogProperties.CACHE_ENABLED));
+}
+
+long cacheExpirationIntervalMs =
+PropertyUtil.propertyAsLong(
+properties,
+CatalogProperties.CACHE_EXPIRATION_INTERVAL_MS,
+CatalogProperties.CACHE_EXPIRATION_INTERVAL_MS_DEFAULT);
+if (cacheExpirationIntervalMs == 0) {
Review Comment:
Not sure why limit to positive numbers, since negative values mean "cache
expiration is turned off and entries expire only on refresh etc", users can set
a negative values.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] luoyuxia commented on issue #3009: How do I realize the upsert of flink sql through setting, in iceberg 0.12.0
luoyuxia commented on issue #3009: URL: https://github.com/apache/iceberg/issues/3009#issuecomment-1305001100 Hi, you can refer to here for [upsert](https://iceberg.apache.org/docs/latest/flink/#upsert) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] luoyuxia commented on issue #3156: Flink reads iceberg in real time and reports errors
luoyuxia commented on issue #3156: URL: https://github.com/apache/iceberg/issues/3156#issuecomment-1305008165 It fail when try to serialize `BaseCombinedScanTask`, I guss it may be fixed by #1285 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] wang-x-xia opened a new pull request, #6132: [0.14] Dell: Fix client serialization bug.
wang-x-xia opened a new pull request, #6132: URL: https://github.com/apache/iceberg/pull/6132 From https://github.com/apache/iceberg/pull/5059. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] wang-x-xia opened a new pull request, #6133: [1.0] Dell: Fix client serialization bug.
wang-x-xia opened a new pull request, #6133: URL: https://github.com/apache/iceberg/pull/6133 From https://github.com/apache/iceberg/pull/5059. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] luoyuxia commented on issue #3124: When writing data to S3 using Glue Catalog, current snapshot ID is -1 and not updated in the metadata file generated
luoyuxia commented on issue #3124: URL: https://github.com/apache/iceberg/issues/3124#issuecomment-1305028751 Have ever a checkpoint been done successfully? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] jzhuge opened a new pull request, #6134: Spec: Add query-column-names to SQL view representation in view spec
jzhuge opened a new pull request, #6134: URL: https://github.com/apache/iceberg/pull/6134 Current view spec misses the field `query-column-names` in SQL view representation. For SELECT star view queries, the schema for the underlying table or view may change after the view has been created. Thus, we need to store the column names of the view query, because when using the view, it is better to pick the columns according to the name and order when the view was created and omit the extra columns we don't require. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] jzhuge commented on pull request #4925: API: Add view interfaces
jzhuge commented on PR #4925: URL: https://github.com/apache/iceberg/pull/4925#issuecomment-1305068781 Created #6134 to add the missing field `query-column-names` to SQL view representation in the view spec. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] zhongyujiang commented on pull request #6118: Parquet, Core: Fix collection of Parquet metrics when column names co…
zhongyujiang commented on PR #6118: URL: https://github.com/apache/iceberg/pull/6118#issuecomment-1305081026 @rdblue sure. When collecting metrics from Parquet footer, Iceberg [converts](https://github.com/apache/iceberg/blob/167a8ccd7c578296c40f8fc61c90135e71cf1183/parquet/src/main/java/org/apache/iceberg/parquet/ParquetUtil.java#L107) the file MessageType to an Iceberg Schema and [uses](https://github.com/apache/iceberg/blob/167a8ccd7c578296c40f8fc61c90135e71cf1183/core/src/main/java/org/apache/iceberg/MetricsUtil.java#L56) this schema to get the column name of an field id it mapping, and then uses the obtained field name to get its corresponding metric mode. However Iceberg will escape special characters in field names when converting an Iceberg Schema to an Parquet MessageType, and those escaped names cannot be restored when converting an Parquet MessageType back to an Iceberg Schema, that is to say, we are now using those escaped column names to get their corresponding metric modes, which may resulted in incorrect results since those escaped names cannot be recognized by MetricsConfig. The ORC path does not have this problem because special characters are not escaped when converting to ORC schema and ORC [itself](https://lists.apache.org/thread/93xbnbs0mr0zxx4fzvrz10m5mmd4qb5w) can handle any UTF-8 characters in the column names. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] zhongyujiang commented on pull request #6118: Parquet, Core: Fix collection of Parquet metrics when column names co…
zhongyujiang commented on PR #6118: URL: https://github.com/apache/iceberg/pull/6118#issuecomment-1305083278 The failure seems unrelated to this PR: >* What went wrong: >Could not determine the dependencies of task ':iceberg-flink:iceberg-flink-runtime-1.16:shadowJar'. >See https://docs.gradle.org/7.5.1/userguide/command_line_interface.html#sec:command_line_warnings > Could not resolve all dependencies for configuration ':iceberg-flink:iceberg-flink-runtime-1.16:runtimeClasspath'. > Could not resolve org.apache.flink:flink-metrics-dropwizard:1.16.0. Required by: project :iceberg-flink:iceberg-flink-runtime-1.16 > Could not resolve org.apache.flink:flink-metrics-dropwizard:1.16.0. > Could not get resource 'https://repo.maven.apache.org/maven2/org/apache/flink/flink-metrics-dropwizard/1.16.0/flink-metrics-dropwizard-1.16.0.pom'. > Could not GET 'https://repo.maven.apache.org/maven2/org/apache/flink/flink-metrics-dropwizard/1.16.0/flink-metrics-dropwizard-1.16.0.pom'. > Connect to repo.maven.apache.org:4[43](https://github.com/apache/iceberg/actions/runs/3407136353/jobs/5666470632#step:4:44) [repo.maven.apache.org/146.75.28.215] failed: connect timed out > -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ajantha-bhat commented on pull request #6094: Spark-3.0: Remove spark/v3.0 folder
ajantha-bhat commented on PR #6094: URL: https://github.com/apache/iceberg/pull/6094#issuecomment-1305136186 cc: @Fokko -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] zhongyujiang commented on a diff in pull request #6118: Parquet, Core: Fix collection of Parquet metrics when column names co…
zhongyujiang commented on code in PR #6118:
URL: https://github.com/apache/iceberg/pull/6118#discussion_r1015035815
##
parquet/src/main/java/org/apache/iceberg/parquet/ParquetUtil.java:
##
@@ -75,23 +76,27 @@ public static Metrics fileMetrics(InputFile file,
MetricsConfig metricsConfig) {
public static Metrics fileMetrics(
InputFile file, MetricsConfig metricsConfig, NameMapping nameMapping) {
try (ParquetFileReader reader =
ParquetFileReader.open(ParquetIO.file(file))) {
- return footerMetrics(reader.getFooter(), Stream.empty(), metricsConfig,
nameMapping);
+ return footerMetrics(reader.getFooter(), Stream.empty(), metricsConfig,
nameMapping, null);
Review Comment:
This is used to migrate external files to Iceberg tables, I am thinking if
those files are generated by Iceberg, we may still not be able to collect
metrics according to the correct metric mode with current change.
To solve this , I think we can change TableMigrationUtil to pass Iceberg
schema also;
Or we can update MetricsConfig to make it tracks mapping between column ids
metric modes, and use column ids to get metric modes directly when collecting
parquet metrics, but that will need all writers to update from
`MetricsConfig.fromProperties(Map props)` to `MetricsConfig
from(Map props, Schema schema, SortOrder order)` (this is a
private method now).
I prefer the second way and I can update the releated code in this repo, but
I don't know if any external projects uses
`MetricsConfig.fromProperties(Map props)` too. What do you
think about it? @rdblue
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ajantha-bhat commented on pull request #6132: [0.14] Dell: Fix client serialization bug.
ajantha-bhat commented on PR #6132: URL: https://github.com/apache/iceberg/pull/6132#issuecomment-1305140708 I think fixing only in the master branch is enough. As per my knowledge, this porting is unnecessary as Iceberg will not do a release for those branches. The next release is 1.1.0, So, if that branch is already made from the master, maybe we need to raise the fix for this branch. cc: @gaborkaszab , @Fokko -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ajantha-bhat commented on pull request #6133: [1.0] Dell: Fix client serialization bug.
ajantha-bhat commented on PR #6133: URL: https://github.com/apache/iceberg/pull/6133#issuecomment-1305140853 I think fixing only in the master branch is enough. As per my knowledge, this porting is unnecessary as Iceberg will not do a release for those branches. The next release is 1.1.0, So, if that branch is already made from the master, maybe we need to raise the fix for this branch. cc: @gaborkaszab , @Fokko -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] wang-x-xia commented on pull request #6132: [0.14] Dell: Fix client serialization bug.
wang-x-xia commented on PR #6132: URL: https://github.com/apache/iceberg/pull/6132#issuecomment-1305142658 @ajantha-bhat Thanks! I'll close this PR~ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] wang-x-xia closed pull request #6132: [0.14] Dell: Fix client serialization bug.
wang-x-xia closed pull request #6132: [0.14] Dell: Fix client serialization bug. URL: https://github.com/apache/iceberg/pull/6132 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] ajantha-bhat commented on pull request #6090: Core: Handle statistics file clean up from expireSnapshots
ajantha-bhat commented on PR #6090: URL: https://github.com/apache/iceberg/pull/6090#issuecomment-1305146273 > @findepi: Thinking more about this, As the TableMetadata has just the list of StatisticsFile. And you have mentioned, statisticsFile.snapshotId() is "ID of the Iceberg table's snapshot the statistics were computed from" So, how will the query knows which statistics file to use for the current snapshot (Incase of rewrite data files, the current snapshot id may not be present in that list of statistics file?) @rdblue, @findepi: Please help in clearing my above doubt. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] hendrikmakait opened a new pull request, #6135: Use pythonic `len()` built-in instead of `length` property
hendrikmakait opened a new pull request, #6135: URL: https://github.com/apache/iceberg/pull/6135 * Replaces `.length` property with the pythonic `__len__` method on `FixedReader` and `FixedType` to enable use of `len()` built-in. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6128: Python: Projection
Fokko commented on code in PR #6128: URL: https://github.com/apache/iceberg/pull/6128#discussion_r1015064168 ## python/pyiceberg/expressions/__init__.py: ## @@ -68,7 +72,6 @@ def eval(self, struct: StructProtocol) -> T: # pylint: disable=W0613 """Returns the value at the referenced field's position in an object that abides by the StructProtocol""" -@dataclass(frozen=True) Review Comment: The rationale is in the PR description. Mostly because my IDE lights up as a Christmas tree, and it is a bit early. It seems that the dataclasses + IDE + mypy don't really know what to do with the inheritance of the different classes. 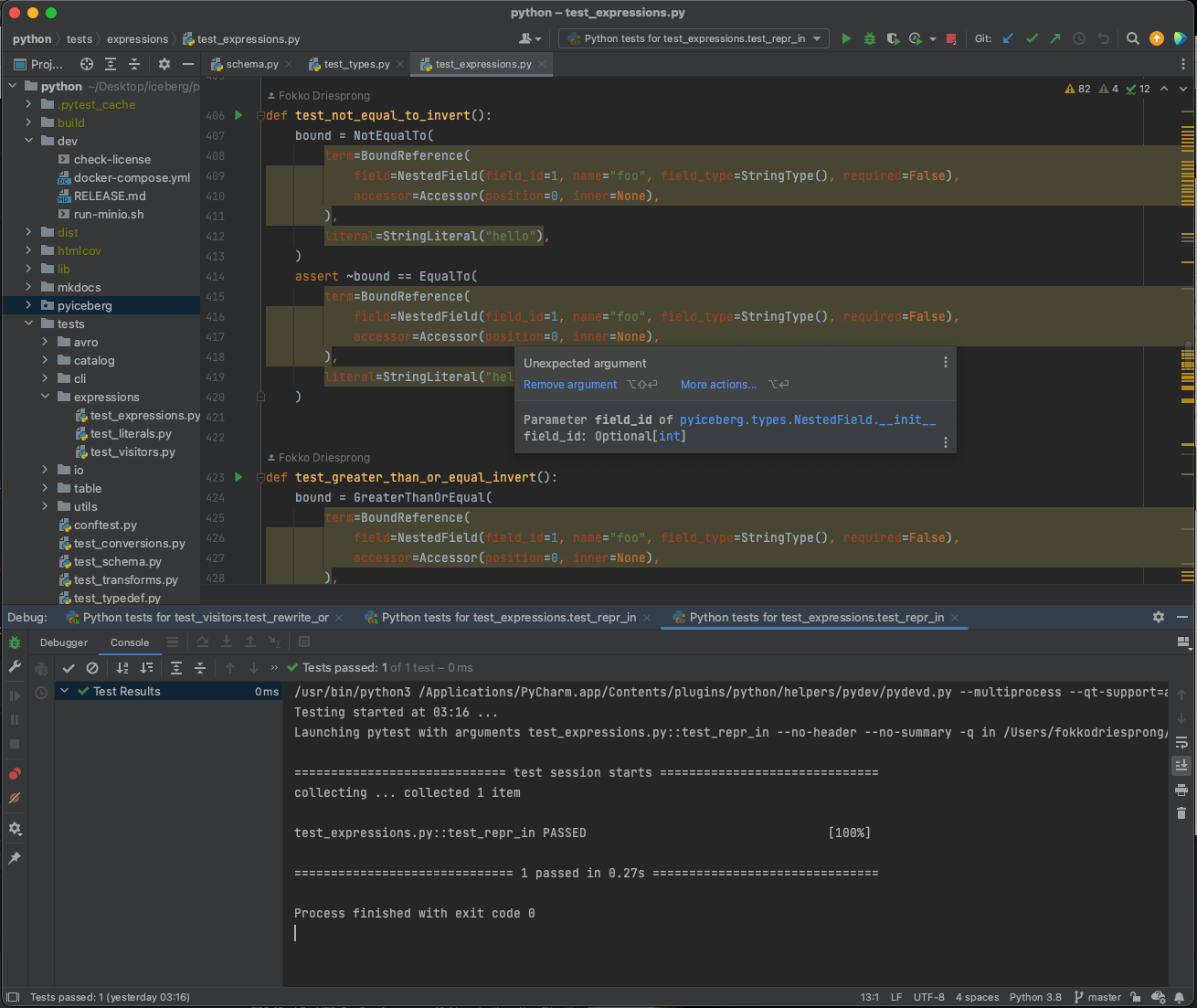 A very slimmed-down example is given in the post around `Reference`:  PyCharm is unable to figure out the argument:  It turns out that you shouldn't use positional arguments with data classes: https://medium.com/@aniscampos/python-dataclass-inheritance-finally-686eaf60fbb5 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra commented on a diff in pull request #6113: Core: Reduce code duplication around writing JSON collections
nastra commented on code in PR #6113:
URL: https://github.com/apache/iceberg/pull/6113#discussion_r1015076718
##
core/src/main/java/org/apache/iceberg/util/JsonUtil.java:
##
@@ -374,4 +380,40 @@ void validate(JsonNode element) {
element);
}
}
+
+ public static void writeIntegerArray(
+ String property, Collection items, JsonGenerator gen) throws
IOException {
Review Comment:
makes sense, updated
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra commented on a diff in pull request #6113: Core: Reduce code duplication around writing JSON collections
nastra commented on code in PR #6113:
URL: https://github.com/apache/iceberg/pull/6113#discussion_r1015078831
##
core/src/main/java/org/apache/iceberg/util/JsonUtil.java:
##
@@ -251,6 +252,11 @@ public static Set getIntegerSet(String property,
JsonNode node) {
.build();
}
+ public static List getLongList(String property, JsonNode node) {
Review Comment:
currently it's only used in the test itself
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra commented on a diff in pull request #5984: Core, API: Support incremental scanning with branch
nastra commented on code in PR #5984:
URL: https://github.com/apache/iceberg/pull/5984#discussion_r1015080916
##
api/src/main/java/org/apache/iceberg/IncrementalScan.java:
##
@@ -21,6 +21,23 @@
/** API for configuring an incremental scan. */
public interface IncrementalScan>
extends Scan {
+
+ /**
+ * Instructs this scan to look for changes starting from a particular
snapshot (inclusive).
+ *
+ * If the start snapshot is not configured, it is defaulted to the oldest
ancestor of the end
+ * snapshot (inclusive).
+ *
+ * @param fromSnapshotId the start snapshot ID (inclusive)
+ * @param referenceName the ref used
+ * @return this for method chaining
+ * @throws IllegalArgumentException if the start snapshot is not an ancestor
of the end snapshot
+ */
+ default ThisT fromSnapshotInclusive(long fromSnapshotId, String
referenceName) {
Review Comment:
> @nastra, the distinction between a branch and a tag here is that a tag
does not change. It doesn't make sense to read incremental changes from a tag
because it is a fixed point in time. So I think it's okay to use `toBranch`
instead of `toRef`, although I'm not sure it's actually worth the distinction
since the other API uses `ref`.
my main point was purely on the naming of the API (`toBranch` vs `toRef`).
It seems to be we could have `toRef()`, which would perform a check to make
sure the given ref is an actual branch
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #6111: Flink: Add 'cache.expiration-interval-ms' option to FlinkCatalog
hililiwei commented on code in PR #6111:
URL: https://github.com/apache/iceberg/pull/6111#discussion_r1015087242
##
flink/v1.14/flink/src/main/java/org/apache/iceberg/flink/FlinkCatalogFactory.java:
##
@@ -145,8 +145,27 @@ protected Catalog createCatalog(
baseNamespace =
Namespace.of(properties.get(BASE_NAMESPACE).split("\\."));
}
-boolean cacheEnabled =
Boolean.parseBoolean(properties.getOrDefault(CACHE_ENABLED, "true"));
-return new FlinkCatalog(name, defaultDatabase, baseNamespace,
catalogLoader, cacheEnabled);
+boolean cacheEnabled = CatalogProperties.CACHE_ENABLED_DEFAULT;
+if (properties.containsKey(CatalogProperties.CACHE_ENABLED)) {
+ cacheEnabled =
Boolean.parseBoolean(properties.get(CatalogProperties.CACHE_ENABLED));
+}
+
+long cacheExpirationIntervalMs =
+PropertyUtil.propertyAsLong(
+properties,
+CatalogProperties.CACHE_EXPIRATION_INTERVAL_MS,
+CatalogProperties.CACHE_EXPIRATION_INTERVAL_MS_DEFAULT);
+if (cacheExpirationIntervalMs == 0) {
Review Comment:
> * If cache.expiration-interval-ms is zero, caching will be turned off
entirely (irrespective of the cache-enabled flag)
> * If cache.expiration-interval-ms is positive (with cache-enabled=true),
then caching will be on and entries will expire if not accessed in that period
of time.
> * If users pass in a value <= -1, (with cache-enabled=true), then caching
will be enabled and cache expiration will never happen (i.e. entries will
persist unless explicitly refreshed, original behavior).
detail ref: https://github.com/apache/iceberg/pull/3543#issue-1052281636
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6069: Python: TableScan Plan files API implementation without residual evaluation
Fokko commented on code in PR #6069: URL: https://github.com/apache/iceberg/pull/6069#discussion_r1015087384 ## python/pyiceberg/expressions/visitors.py: ## @@ -517,7 +519,7 @@ def visit_equal(self, term: BoundTerm, literal: Literal[Any]) -> bool: pos = term.ref().accessor.position field = self.partition_fields[pos] -if field.lower_bound is None: +if field.lower_bound is None or field.upper_bound is None: Review Comment: This is required for the linter since we're the variable below. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on pull request #6075: Flink 1.15: Support change log scan task
hililiwei commented on PR #6075: URL: https://github.com/apache/iceberg/pull/6075#issuecomment-1305209915 @stevenzwu could you please take a look at it when you get a chance? thx. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] chenwyi2 opened a new issue, #6136: if i lost a metadata file, how to recover
chenwyi2 opened a new issue, #6136: URL: https://github.com/apache/iceberg/issues/6136 ### Query engine spark: 3.1 iceberg: 0.14.1 ### Question the situation is, i had a table partition by date, and i deleted a old manifest file from hdfs without moving to trash, and i want to delete some partitions which are older than 10 days, but i got error: filenotfoundexcaption(that deleted old manifest file), how can i solve this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra commented on a diff in pull request #6073: Core: Pass purgeRequested flag to REST server
nastra commented on code in PR #6073:
URL: https://github.com/apache/iceberg/pull/6073#discussion_r1015101336
##
core/src/test/java/org/apache/iceberg/catalog/CatalogTests.java:
##
@@ -799,6 +799,23 @@ public void testDropTable() {
Assert.assertFalse("Table should not exist after drop",
catalog.tableExists(TABLE));
}
+ @Test
+ public void testDropTableWithPurge() {
+C catalog = catalog();
+
+if (requiresNamespaceCreate()) {
+ catalog.createNamespace(NS);
+}
+
+Assertions.assertThat(catalog.tableExists(TABLE)).isFalse();
+
+catalog.buildTable(TABLE, SCHEMA).create();
+Assertions.assertThat(catalog.tableExists(TABLE)).isTrue();
+
+Assertions.assertThat(catalog.dropTable(TABLE, true)).isTrue();
+Assertions.assertThat(catalog.tableExists(TABLE)).isFalse();
Review Comment:
done
##
core/src/main/java/org/apache/iceberg/rest/CatalogHandlers.java:
##
@@ -222,13 +222,27 @@ public static LoadTableResponse createTable(
throw new IllegalStateException("Cannot wrap catalog that does not produce
BaseTable");
}
+ /**
+ * @param catalog The catalog instance
+ * @param ident The table identifier of the table to be dropped.
+ * @deprecated Will be removed in 1.2.0, use {@link
CatalogHandlers#dropTable(Catalog,
+ * TableIdentifier, boolean)}.
+ */
+ @Deprecated
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org