[GitHub] [iceberg] nastra commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
nastra commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1050439739
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
Review Comment:
do we have a more specific type for the config? `Object` seems a little bit
too generic
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snow
[GitHub] [iceberg] nastra commented on a diff in pull request #5837: API,Core: Introduce metrics for data files by file format
nastra commented on code in PR #5837:
URL: https://github.com/apache/iceberg/pull/5837#discussion_r1050492924
##
api/src/main/java/org/apache/iceberg/metrics/MultiDimensionCounterKey.java:
##
@@ -0,0 +1,26 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.metrics;
+
+// TODO gaborkaszab: comment
+public interface MultiDimensionCounterKey {
Review Comment:
rather than calling this `MultiDimensionCounterKey` I think a better name
would be `MetricTag`. Micrometer also uses tag(s) as a term for multiple
dimensions.
##
api/src/main/java/org/apache/iceberg/metrics/MultiDimensionCounterKey.java:
##
@@ -0,0 +1,26 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.metrics;
+
+// TODO gaborkaszab: comment
+public interface MultiDimensionCounterKey {
+ String get();
+
+ int numDimensions();
Review Comment:
I'm a bit confused why this method is needed
##
core/src/main/java/org/apache/iceberg/metrics/MultiDimensionCounterResultParser.java:
##
@@ -0,0 +1,95 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.metrics;
+
+import com.fasterxml.jackson.core.JsonGenerator;
+import com.fasterxml.jackson.databind.JsonNode;
+import com.fasterxml.jackson.databind.node.ArrayNode;
+import java.io.IOException;
+import java.util.Iterator;
+import java.util.Map;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.JsonUtil;
+
+public class MultiDimensionCounterResultParser {
+ private static final String MISSING_FIELD_ERROR_MSG =
+ "Cannot parse counter from '%s': Missing field '%s'";
+ private static final String UNIT = "unit";
+ private static final String VALUE = "value";
+ private static final String COUNTER_ID = "counter-id";
Review Comment:
why do we use `counter-id`? Isn't this just a nested `CounterResult` where
we can use `CounterResultParser` for ser/de?
##
core/src/main/java/org/apache/iceberg/metrics/MultiDimensionCounterResult.java:
##
@@ -0,0 +1,69 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.
[GitHub] [iceberg] nastra commented on a diff in pull request #5837: API,Core: Introduce metrics for data files by file format
nastra commented on code in PR #5837:
URL: https://github.com/apache/iceberg/pull/5837#discussion_r1050495424
##
api/src/main/java/org/apache/iceberg/metrics/MultiDimensionCounterKey.java:
##
@@ -0,0 +1,26 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.metrics;
+
+// TODO gaborkaszab: comment
+public interface MultiDimensionCounterKey {
+ String get();
+
+ int numDimensions();
Review Comment:
I'm a bit confused why this method is needed. Could you elaborate please?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050533828
##
python/pyiceberg/expressions/visitors.py:
##
@@ -753,3 +757,68 @@ def inclusive_projection(
schema: Schema, spec: PartitionSpec, case_sensitive: bool = True
) -> Callable[[BooleanExpression], BooleanExpression]:
return InclusiveProjection(schema, spec, case_sensitive).project
+
+
+class _ExpressionProjector(BooleanExpressionVisitor[BooleanExpression]):
+"""Rewrites a boolean expression by replacing unbound references with
references to fields in a struct schema
+
+Args:
+ table_schema (Schema): The schema of the table
+ file_schema (Schema): The schema of the file
+ case_sensitive (bool): Whether to consider case when binding a reference
to a field in a schema, defaults to True
+
+Raises:
+TypeError: In the case a predicate is already bound
+"""
+
+table_schema: Schema
+file_schema: Schema
+case_sensitive: bool
+
+def __init__(self, table_schema: Schema, file_schema: Schema,
case_sensitive: bool) -> None:
+self.table_schema = table_schema
+self.file_schema = file_schema
+self.case_sensitive = case_sensitive
+
+def visit_true(self) -> BooleanExpression:
+return AlwaysTrue()
+
+def visit_false(self) -> BooleanExpression:
+return AlwaysFalse()
+
+def visit_not(self, child_result: BooleanExpression) -> BooleanExpression:
+return Not(child=child_result)
+
+def visit_and(self, left_result: BooleanExpression, right_result:
BooleanExpression) -> BooleanExpression:
+return And(left=left_result, right=right_result)
+
+def visit_or(self, left_result: BooleanExpression, right_result:
BooleanExpression) -> BooleanExpression:
+return Or(left=left_result, right=right_result)
+
+def visit_unbound_predicate(self, predicate: UnboundPredicate[L]) ->
BooleanExpression:
+if not isinstance(predicate.term, Reference):
+raise ValueError(f"Exprected reference: {predicate.term}")
+
+field = self.table_schema.find_field(predicate.term.name,
case_sensitive=self.case_sensitive)
+file_column_name = self.file_schema.find_column_name(field.field_id)
+
+if not file_column_name:
+raise ValueError(f"Not found in schema: {file_column_name}")
+
+if isinstance(predicate, UnaryPredicate):
+return predicate.__class__(Reference(file_column_name))
Review Comment:
Ah, I see. I think it is nicer to convert it back to an unbound expression,
and then bind that with the file schema. Let me update the code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437: URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050535352 ## python/pyiceberg/expressions/visitors.py: ## @@ -753,3 +757,68 @@ def inclusive_projection( schema: Schema, spec: PartitionSpec, case_sensitive: bool = True ) -> Callable[[BooleanExpression], BooleanExpression]: return InclusiveProjection(schema, spec, case_sensitive).project + + +class _ExpressionProjector(BooleanExpressionVisitor[BooleanExpression]): Review Comment: I called it first a translator, and then went with projection :p -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050552255
##
python/pyiceberg/io/pyarrow.py:
##
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+file_schema: Schema
+table: pa.Table
+
+def __init__(self, file_schema: Schema, table: pa.Table):
+self.file_schema = file_schema
+self.table = table
+
+def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+return field_results
+
+def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+column_name = self.file_schema.find_column_name(field.field_id)
+
+if column_name:
+column_idx = self.table.schema.get_field_index(column_name)
+else:
+column_idx = -1
+
+expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+# The idx will be -1 when the column can't be found
+if column_idx >= 0:
+column_field: pa.Field = self.table.schema[column_idx]
+column_arrow_type: pa.DataType = column_field.type
+column_data: pa.ChunkedArray = self.table[column_idx]
+
+# In case of schema evolution
+if column_arrow_type != expected_arrow_type:
+column_data = column_data.cast(expected_arrow_type)
+else:
+import numpy as np
+
+column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+return column_data
+
+def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+pass
+
+def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+pass
+
+def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+if isinstance(table.io, PyArrowFileIO):
+scheme, path = PyArrowFileIO.parse_location(table.location())
+fs = table.io.get_fs(scheme)
+else:
+raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+projected_field_ids = projected_schema.field_ids
+
+tables = []
+for task in files:
+_, path = PyArrowFileIO.parse_location(task.file.file_path)
+
+# Get the schema
+with fs.open_input_file(path) as fout:
+parquet_schema = pq.read_schema(fout)
+schema_raw = parquet_schema.metadata.get(ICEBERG_SCHEMA)
+file_schema = Schema.parse_raw(schema_raw)
+
+file_project_schema = prune_columns(file_schema, projected_field_ids)
+
+pyarrow_filter = None
+if row_filter is not AlwaysTrue():
+row_filter = project_expression(row_filter, table.schema(),
file_schema, case_sensitive=case_sensitive)
+bound_row_filter = bind(file_schema, row_filter,
case_sensitive=case_sensitive)
+pyarrow_filter = expression_to_pyarrow(bound_row_filter)
+
+if file_schema is None:
+raise ValueError(f"Iceberg schema not encoded in Parquet file:
{path}")
Review Comment:
Fair point, I've changed this to: `Missing Iceberg schema in Metadata for
file: {path}`. I think it is important to also mention that it is not found in
the metadata
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] gaborkaszab commented on a diff in pull request #6074: API,Core: SnapshotManager to be created through Transaction
gaborkaszab commented on code in PR #6074:
URL: https://github.com/apache/iceberg/pull/6074#discussion_r1050562294
##
core/src/main/java/org/apache/iceberg/SnapshotManager.java:
##
@@ -30,6 +31,17 @@ public class SnapshotManager implements ManageSnapshots {
ops.current() != null, "Cannot manage snapshots: table %s does not
exist", tableName);
this.transaction =
new BaseTransaction(tableName, ops,
BaseTransaction.TransactionType.SIMPLE, ops.refresh());
+this.isExternalTransaction = false;
+ }
+
+ SnapshotManager(BaseTransaction transaction) {
+Preconditions.checkNotNull(transaction, "Input transaction cannot be
null");
+Preconditions.checkNotNull(
Review Comment:
Ohh, I totally misunderstood your comment then, and writing such a long
answer wasn't necessary at all :)
This precondition is let's say partially intentional as I wanted to follow
the existing constructor that has a [similar
check](https://github.com/apache/iceberg/blob/c07f2aabc0a1d02f068ecf1514d2479c0fbdd3b0/core/src/main/java/org/apache/iceberg/SnapshotManager.java#L29).
After giving this a thought this check might make sense as everything in
SnapshotManager requires snapshot IDs or branch names that we won't have with a
createTransaction().
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] gaborkaszab commented on a diff in pull request #6074: API,Core: SnapshotManager to be created through Transaction
gaborkaszab commented on code in PR #6074:
URL: https://github.com/apache/iceberg/pull/6074#discussion_r1050562294
##
core/src/main/java/org/apache/iceberg/SnapshotManager.java:
##
@@ -30,6 +31,17 @@ public class SnapshotManager implements ManageSnapshots {
ops.current() != null, "Cannot manage snapshots: table %s does not
exist", tableName);
this.transaction =
new BaseTransaction(tableName, ops,
BaseTransaction.TransactionType.SIMPLE, ops.refresh());
+this.isExternalTransaction = false;
+ }
+
+ SnapshotManager(BaseTransaction transaction) {
+Preconditions.checkNotNull(transaction, "Input transaction cannot be
null");
+Preconditions.checkNotNull(
Review Comment:
Thanks for the clarification, @rdblue! I totally misunderstood your comment
then, and writing such a long answer wasn't necessary at all :)
This precondition is let's say partially intentional as I wanted to follow
the existing constructor that has a [similar
check](https://github.com/apache/iceberg/blob/c07f2aabc0a1d02f068ecf1514d2479c0fbdd3b0/core/src/main/java/org/apache/iceberg/SnapshotManager.java#L29).
After giving this a thought this check might make sense as everything in
SnapshotManager requires snapshot IDs or branch names that we won't have with a
createTransaction().
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] gaborkaszab commented on issue #6257: Partitions metadata table shows old partitions
gaborkaszab commented on issue #6257: URL: https://github.com/apache/iceberg/issues/6257#issuecomment-1354499343 > Looks like without `USING iceberg` you don't create iceberg table and so it doesn't have to have even update support not speaking about partitions table https://user-images.githubusercontent.com/825753/207952294-0da9a7c4-d660-4441-87ca-40dc86cadb37.png";> Hey @bondarenko You're saying that you weren't able to repro the issue with the SQL in the description? I definitely had an Iceberg table, was able to update and also to query metadata tables (that are Iceberg specific). There might be a setting to default the `CREATE TABLE` to Iceberg, I don't know. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050575140
##
python/pyiceberg/io/pyarrow.py:
##
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+file_schema: Schema
+table: pa.Table
+
+def __init__(self, file_schema: Schema, table: pa.Table):
+self.file_schema = file_schema
+self.table = table
+
+def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+return field_results
+
+def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+column_name = self.file_schema.find_column_name(field.field_id)
+
+if column_name:
+column_idx = self.table.schema.get_field_index(column_name)
+else:
+column_idx = -1
+
+expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+# The idx will be -1 when the column can't be found
+if column_idx >= 0:
+column_field: pa.Field = self.table.schema[column_idx]
+column_arrow_type: pa.DataType = column_field.type
+column_data: pa.ChunkedArray = self.table[column_idx]
+
+# In case of schema evolution
+if column_arrow_type != expected_arrow_type:
+column_data = column_data.cast(expected_arrow_type)
+else:
+import numpy as np
+
+column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+return column_data
+
+def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+pass
+
+def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+pass
+
+def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+if isinstance(table.io, PyArrowFileIO):
+scheme, path = PyArrowFileIO.parse_location(table.location())
+fs = table.io.get_fs(scheme)
+else:
+raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+projected_field_ids = projected_schema.field_ids
+
+tables = []
+for task in files:
+_, path = PyArrowFileIO.parse_location(task.file.file_path)
+
+# Get the schema
+with fs.open_input_file(path) as fout:
+parquet_schema = pq.read_schema(fout)
+schema_raw = parquet_schema.metadata.get(ICEBERG_SCHEMA)
+file_schema = Schema.parse_raw(schema_raw)
+
+file_project_schema = prune_columns(file_schema, projected_field_ids)
+
+pyarrow_filter = None
+if row_filter is not AlwaysTrue():
+row_filter = project_expression(row_filter, table.schema(),
file_schema, case_sensitive=case_sensitive)
+bound_row_filter = bind(file_schema, row_filter,
case_sensitive=case_sensitive)
+pyarrow_filter = expression_to_pyarrow(bound_row_filter)
+
+if file_schema is None:
+raise ValueError(f"Iceberg schema not encoded in Parquet file:
{path}")
+
+# Prune the stuff that we don't need anyway
+file_project_schema_arrow = schema_to_pyarrow(file_project_schema)
+
+arrow_table = ds.dataset(
Review Comment:
I've added tests for both of them. If a column isn't there, we create a
PyArrow buffer, filled with `null`s. I noticed that in [Python
legacy](https://github.com/apache/iceberg/blob/master/python_legacy/iceberg/parquet/parquet_reader.py#L43-L67),
we filled with `{}`, `[]`, `np.NaN` etc, but that makes less sense to me.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050582655
##
python/pyiceberg/io/pyarrow.py:
##
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+file_schema: Schema
+table: pa.Table
+
+def __init__(self, file_schema: Schema, table: pa.Table):
+self.file_schema = file_schema
+self.table = table
+
+def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+return field_results
+
+def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+column_name = self.file_schema.find_column_name(field.field_id)
+
+if column_name:
+column_idx = self.table.schema.get_field_index(column_name)
+else:
+column_idx = -1
+
+expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+# The idx will be -1 when the column can't be found
+if column_idx >= 0:
+column_field: pa.Field = self.table.schema[column_idx]
+column_arrow_type: pa.DataType = column_field.type
+column_data: pa.ChunkedArray = self.table[column_idx]
+
+# In case of schema evolution
+if column_arrow_type != expected_arrow_type:
+column_data = column_data.cast(expected_arrow_type)
+else:
+import numpy as np
+
+column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+return column_data
+
+def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+pass
+
+def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+pass
+
+def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+if isinstance(table.io, PyArrowFileIO):
+scheme, path = PyArrowFileIO.parse_location(table.location())
+fs = table.io.get_fs(scheme)
+else:
+raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+projected_field_ids = projected_schema.field_ids
+
+tables = []
+for task in files:
Review Comment:
I think it would make more sense to make this part of the task, but lets do
that in a separate PR
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050583093
##
python/pyiceberg/io/pyarrow.py:
##
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+file_schema: Schema
+table: pa.Table
+
+def __init__(self, file_schema: Schema, table: pa.Table):
+self.file_schema = file_schema
+self.table = table
+
+def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+return field_results
+
+def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+column_name = self.file_schema.find_column_name(field.field_id)
+
+if column_name:
+column_idx = self.table.schema.get_field_index(column_name)
+else:
+column_idx = -1
+
+expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+# The idx will be -1 when the column can't be found
+if column_idx >= 0:
+column_field: pa.Field = self.table.schema[column_idx]
+column_arrow_type: pa.DataType = column_field.type
+column_data: pa.ChunkedArray = self.table[column_idx]
+
+# In case of schema evolution
+if column_arrow_type != expected_arrow_type:
+column_data = column_data.cast(expected_arrow_type)
+else:
+import numpy as np
+
+column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+return column_data
+
+def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+pass
+
+def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+pass
+
+def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+if isinstance(table.io, PyArrowFileIO):
+scheme, path = PyArrowFileIO.parse_location(table.location())
+fs = table.io.get_fs(scheme)
+else:
+raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+projected_field_ids = projected_schema.field_ids
+
+tables = []
+for task in files:
+_, path = PyArrowFileIO.parse_location(task.file.file_path)
+
+# Get the schema
+with fs.open_input_file(path) as fout:
+parquet_schema = pq.read_schema(fout)
+schema_raw = parquet_schema.metadata.get(ICEBERG_SCHEMA)
+file_schema = Schema.parse_raw(schema_raw)
+
+file_project_schema = prune_columns(file_schema, projected_field_ids)
+
+pyarrow_filter = None
+if row_filter is not AlwaysTrue():
+row_filter = project_expression(row_filter, table.schema(),
file_schema, case_sensitive=case_sensitive)
+bound_row_filter = bind(file_schema, row_filter,
case_sensitive=case_sensitive)
+pyarrow_filter = expression_to_pyarrow(bound_row_filter)
+
+if file_schema is None:
+raise ValueError(f"Iceberg schema not encoded in Parquet file:
{path}")
+
+# Prune the stuff that we don't need anyway
+file_project_schema_arrow = schema_to_pyarrow(file_project_schema)
+
+arrow_table = ds.dataset(
Review Comment:
In case of promotion, we convert the buffer:
```python
# In case of schema evolution
if column_arrow_type != expected_arrow_type:
column_data = column_data.cast(expected_arrow_type)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6437: Python: Projection by Field ID
Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050587798
##
python/pyiceberg/io/pyarrow.py:
##
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+file_schema: Schema
+table: pa.Table
+
+def __init__(self, file_schema: Schema, table: pa.Table):
+self.file_schema = file_schema
+self.table = table
+
+def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+return field_results
+
+def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+column_name = self.file_schema.find_column_name(field.field_id)
+
+if column_name:
+column_idx = self.table.schema.get_field_index(column_name)
+else:
+column_idx = -1
+
+expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+# The idx will be -1 when the column can't be found
+if column_idx >= 0:
+column_field: pa.Field = self.table.schema[column_idx]
+column_arrow_type: pa.DataType = column_field.type
+column_data: pa.ChunkedArray = self.table[column_idx]
+
+# In case of schema evolution
+if column_arrow_type != expected_arrow_type:
+column_data = column_data.cast(expected_arrow_type)
+else:
+import numpy as np
+
+column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+return column_data
+
+def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+pass
+
+def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+pass
+
+def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+if isinstance(table.io, PyArrowFileIO):
+scheme, path = PyArrowFileIO.parse_location(table.location())
+fs = table.io.get_fs(scheme)
+else:
+raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+projected_field_ids = projected_schema.field_ids
+
+tables = []
+for task in files:
+_, path = PyArrowFileIO.parse_location(task.file.file_path)
+
+# Get the schema
+with fs.open_input_file(path) as fout:
+parquet_schema = pq.read_schema(fout)
+schema_raw = parquet_schema.metadata.get(ICEBERG_SCHEMA)
+file_schema = Schema.parse_raw(schema_raw)
+
+file_project_schema = prune_columns(file_schema, projected_field_ids)
Review Comment:
Yes, this will prune the fields that we don't need, so we only load the
column that we're going to need, lowering the pressure on the memory. The magic
to match the schema happens in `to_final_schema`, and then we just concat the
tables. Since the table is already in the correct format, we can just concat
them, with the zero-copy concatenation:
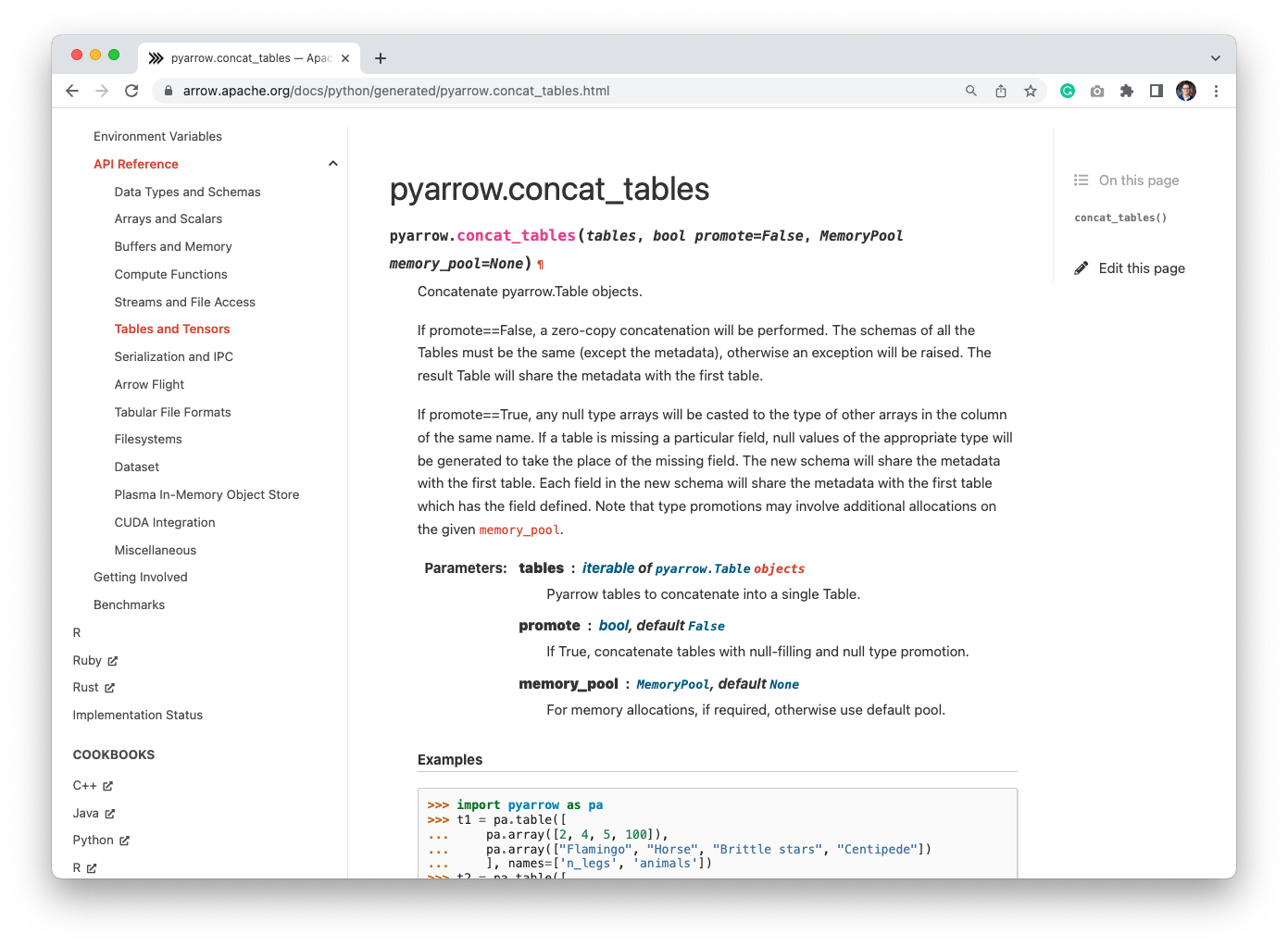
We could also let PyArrow do the null-filling and promotions, but maybe
better to do it ourselves, especially when we start doing things like default
values.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra commented on issue #6099: Flink: Add support for Flink 1.16
nastra commented on issue #6099: URL: https://github.com/apache/iceberg/issues/6099#issuecomment-1354541184 given that #6092 is merged, we can close this one out -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra closed issue #6099: Flink: Add support for Flink 1.16
nastra closed issue #6099: Flink: Add support for Flink 1.16 URL: https://github.com/apache/iceberg/issues/6099 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] nastra opened a new pull request, #6441: Run weekly JMH Benchmarks & visualize results
nastra opened a new pull request, #6441: URL: https://github.com/apache/iceberg/pull/6441 This runs the JMH Benchmarks every Sunday and also create a visual report for each benchmark and upload it after all benchmarks completed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] findepi opened a new issue, #6442: Extends Iceberg table stats API to allow publish data and stats atomically
findepi opened a new issue, #6442: URL: https://github.com/apache/iceberg/issues/6442 ### Feature Request / Improvement Currently `UpdateStatistics` (`org.apache.iceberg.Transaction#updateStatistics`) allows adding statistics for an existing snapshot. As a result, it is currently not possible publish a snapshot with statistics already collected. Collecting statistics for an existing data is definitely an important use-case (like Trino's ANALYZE), but some query engines (like Trino) can collect stats on the fly, when writing to a table (INSERT, CREATE TABLE AS ...). It's not difficult to - publish data change snapshot (adding new files) - take a note of new snapshot ID - add statistics for that snapshot however this has some drawbacks - new data is published without stats, so other queries can be planned sub-optimally, leading to eg improper use of cluster resources, or even unexpected query failures (if data changed significantly) - someone may run ANALYZE on the new snapshot (unknowingly or intentionally), and this will end up with two different threads wanting to add stats to it -- wasted work We should make it possible to publish data change together with new stats. This may will require API changes It may also require spec changes, if we want to use "inherit snapshot ID" model. (Maybe we don't have to, since stats are in metadata?) ### Query engine None -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] findepi commented on issue #6442: Extends Iceberg table stats API to allow publish data and stats atomically
findepi commented on issue #6442: URL: https://github.com/apache/iceberg/issues/6442#issuecomment-1355104260 cc @rdblue -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] findepi opened a new issue, #6443: Provide Puffin reader API allowing read without decompression
findepi opened a new issue, #6443: URL: https://github.com/apache/iceberg/issues/6443 ### Feature Request / Improvement When a query engine wants to add new stats to a snapshot that already has some stats, it currently needs to merge existing stats file' blobs with new ones. Currently, the only Puffin reader API for reading blobs will decompress them implicitly. The application merging stats probably doesn't know much about these old stats, so also doesn't know whether they should be compressed, so it should preserve the compression. Thus it will want to re-compress them again. - This process is wasteful: redundant decompression and compression - Also, it is not possible to implement it in a future-proof manner: application can preserve compression only for the puffin codecs it was built with ### Query engine None -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] lvyanquan opened a new pull request, #6444: Docs: add example of spark extension for identifier fields
lvyanquan opened a new pull request, #6444: URL: https://github.com/apache/iceberg/pull/6444 add doc for this extension https://github.com/apache/iceberg/pull/2560 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] InvisibleProgrammer opened a new pull request, #189: Docs: Update hive docs 1.0.0
InvisibleProgrammer opened a new pull request, #189: URL: https://github.com/apache/iceberg-docs/pull/189 Porting recent documentation changes on hive integration: https://github.com/apache/iceberg/pull/6337 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] InvisibleProgrammer opened a new pull request, #188: Docs: Update Iceberg Hive documentation (#6337)
InvisibleProgrammer opened a new pull request, #188: URL: https://github.com/apache/iceberg-docs/pull/188 Porting recent documentation changes on hive integration: https://github.com/apache/iceberg/pull/6337 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] InvisibleProgrammer opened a new pull request, #190: Docs: Update hive docs 1.1.0
InvisibleProgrammer opened a new pull request, #190: URL: https://github.com/apache/iceberg-docs/pull/190 Porting recent documentation changes on hive integration: https://github.com/apache/iceberg/pull/6337 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] InvisibleProgrammer commented on pull request #6379: Docs: Update Iceberg Hive documentation - 1.0.x (#6337)
InvisibleProgrammer commented on PR #6379: URL: https://github.com/apache/iceberg/pull/6379#issuecomment-1355156829 I think I've found the proper way to update the documentation for older versions. What do you think, is that the correct way? - 0.14.1: https://github.com/apache/iceberg-docs/pull/188 - 1.0.0: https://github.com/apache/iceberg-docs/pull/189 - 1.1.0: https://github.com/apache/iceberg-docs/pull/190 Thank you, Zsolt -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] InvisibleProgrammer commented on issue #6249: Update Iceberg Hive documentation
InvisibleProgrammer commented on issue #6249: URL: https://github.com/apache/iceberg/issues/6249#issuecomment-1355157632 PRs for older versions: - 0.14.1: https://github.com/apache/iceberg-docs/pull/188 - 1.0.0: https://github.com/apache/iceberg-docs/pull/189 - 1.1.0: https://github.com/apache/iceberg-docs/pull/190 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] danielcweeks merged pull request #184: Add CelerData in vendors page
danielcweeks merged PR #184: URL: https://github.com/apache/iceberg-docs/pull/184 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
rdblue commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1050931726
##
orc/src/main/java/org/apache/iceberg/orc/FileIOFSUtil.java:
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.orc;
+
+import java.io.FileNotFoundException;
+import java.io.IOException;
+import java.io.OutputStream;
+import java.net.URI;
+import org.apache.hadoop.fs.FSDataInputStream;
+import org.apache.hadoop.fs.FSDataOutputStream;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.permission.FsPermission;
+import org.apache.hadoop.util.Progressable;
+import org.apache.iceberg.hadoop.HadoopStreams;
+import org.apache.iceberg.io.InputFile;
+import org.apache.iceberg.io.OutputFile;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+
+public class FileIOFSUtil {
Review Comment:
I don't think this should be public. Could you make it package-private?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
rdblue commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1050934075
##
orc/src/main/java/org/apache/iceberg/orc/ORC.java:
##
@@ -789,7 +808,210 @@ static Reader newFileReader(InputFile file, Configuration
config) {
ReaderOptions readerOptions =
OrcFile.readerOptions(config).useUTCTimestamp(true);
if (file instanceof HadoopInputFile) {
readerOptions.filesystem(((HadoopInputFile) file).getFileSystem());
+} else {
Review Comment:
Yeah, rather than deprecating we should just remove it if it isn't public.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
rdblue commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1050935078
##
orc/src/test/java/org/apache/iceberg/orc/TestOrcDataWriter.java:
##
@@ -126,4 +135,116 @@ public void testDataWriter() throws IOException {
Assert.assertEquals("Written records should match", records,
writtenRecords);
}
+
+ @Test
+ public void testUsingFileIO() throws IOException {
+// Show that FileSystem access is not possible for the file we are
supplying as the scheme
+// dummy is not handled
+ProxyOutputFile outFile = new
ProxyOutputFile(Files.localOutput(temp.newFile()));
+Assertions.assertThatThrownBy(
+() -> HadoopOutputFile.fromPath(new Path(outFile.location()), new
Configuration()))
+.isInstanceOf(RuntimeIOException.class)
+.hasMessageStartingWith("Failed to get file system for path: dummy");
+
+// We are creating the proxy
+SortOrder sortOrder =
SortOrder.builderFor(SCHEMA).withOrderId(10).asc("id").build();
+
+DataWriter dataWriter =
+ORC.writeData(outFile)
+.schema(SCHEMA)
+.createWriterFunc(GenericOrcWriter::buildWriter)
+.overwrite()
+.withSpec(PartitionSpec.unpartitioned())
Review Comment:
Do we need to add `withSpec` or will it use the unpartitioned spec by
default?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] pvary merged pull request #188: Docs: Update Iceberg Hive documentation (#6337)
pvary merged PR #188: URL: https://github.com/apache/iceberg-docs/pull/188 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] pvary merged pull request #190: Docs: Update hive docs 1.1.0
pvary merged PR #190: URL: https://github.com/apache/iceberg-docs/pull/190 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg-docs] pvary merged pull request #189: Docs: Update hive docs 1.0.0
pvary merged PR #189: URL: https://github.com/apache/iceberg-docs/pull/189 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] manisin commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
manisin commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051059938
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
Review Comment:
The decision to use Object rather than HadoopConfig is to avoid runtime time
dependency on hadoop packages. This usage pattern is inline with other catalogs
like GlueCatalog.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] szehon-ho commented on a diff in pull request #6433: Docs: README
szehon-ho commented on code in PR #6433: URL: https://github.com/apache/iceberg/pull/6433#discussion_r1051058098 ## README.md: ## @@ -34,7 +34,7 @@ Iceberg is under active development at the Apache Software Foundation. The core Java library that tracks table snapshots and metadata is complete, but still evolving. Current work is focused on adding row-level deletes and upserts, and integration work with new engines like Flink and Hive. -The [Iceberg format specification][iceberg-spec] is being actively updated and is open for comment. Until the specification is complete and released, it carries no compatibility guarantees. The spec is currently evolving as the Java reference implementation changes. +The [Iceberg format specification][iceberg-spec] is being actively updated (as the Java reference implementation changes) and is open for comments. Until the specification is complete and released, it carries no compatibility guarantees. Review Comment: Probably we can say there are compatibility guarantees for V1/V2 specs now, but itd be a bigger discussion how to phrase it. So ok with this for now -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] manisin commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
manisin commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051066674
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
Review Comment:
The intention here is that regardless of the client implementation, the
Snowflake data model doesn't support more than 2 levels of namespace.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
issues@iceberg.apache.org
haizhou-zhao commented on code in PR #6324:
URL: https://github.com/apache/iceberg/pull/6324#discussion_r1051069226
##
hive-metastore/src/main/java/org/apache/iceberg/hive/HiveTableOperations.java:
##
@@ -422,11 +425,21 @@ private Table newHmsTable(TableMetadata metadata) {
Preconditions.checkNotNull(metadata, "'metadata' parameter can't be null");
final long currentTimeMillis = System.currentTimeMillis();
+String defaultUser;
+try {
Review Comment:
Ack, taken
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
issues@iceberg.apache.org
haizhou-zhao commented on PR #6324: URL: https://github.com/apache/iceberg/pull/6324#issuecomment-1355443482 > > Hey folks, comments from last round of review all taken and implemented. > > Specifically, on one comment: @gaborkaszab @szehon-ho I removed support for changing ownership for tables from this PR. But before I committed to create a follow up PR on that, I want to double check and make sure if you guys feel these worth implementing (which are something we do not have today): > > > > 1. When user remove ownership on a table, revert the owner of the table to default owner (current UGI) > > 2. When user alter the ownership on a table, change the owner of table accordingly > > I think it does make sense to have a support for altering ownership. Impala has "ALTER TABLE xy SET OWNER" for this purpose, and I guess Hive also has something similar. Yes, the use-cases 1) and 2) you mention make sense for me. Thank you @gaborkaszab , I create a follow up PR for those use cases. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rubenvdg opened a new pull request, #6445: Python: Mock home and root folder when running `test_missing_uri`
rubenvdg opened a new pull request, #6445: URL: https://github.com/apache/iceberg/pull/6445 This could be a way to alleviate this issue https://github.com/apache/iceberg/issues/6361. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rubenvdg commented on issue #6397: Python Instructions currently do not work for testing
rubenvdg commented on issue #6397: URL: https://github.com/apache/iceberg/issues/6397#issuecomment-1355516952 Yes agreed! It's already part of https://github.com/apache/iceberg/pull/6438, right? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on issue #6397: Python Instructions currently do not work for testing
Fokko commented on issue #6397: URL: https://github.com/apache/iceberg/issues/6397#issuecomment-1355517950 @rubenvdg Yes, I was doing some refactoring yesterday, and also included it in there 👍🏻 Feel free to review the PR :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] manisin commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
manisin commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051114634
##
snowflake/src/main/java/org/apache/iceberg/snowflake/entities/SnowflakeTable.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake.entities;
+
+import java.util.List;
+import org.apache.commons.dbutils.ResultSetHandler;
+import org.apache.iceberg.relocated.com.google.common.base.Objects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class SnowflakeTable {
+ private String databaseName;
+ private String schemaName;
+ private String name;
+
+ public SnowflakeTable(String databaseName, String schemaName, String name) {
Review Comment:
SnowflakeTable/SnowflakeSchema defines the entities in terms of snowflake's
object model and is used to define the contract with the SnowflakeClient. We
expect this to evolve independently of the iceberg's corresponding classes by
allowing different behavior and members.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6445: Python: Mock home and root folder when running `test_missing_uri`
rdblue commented on PR #6445: URL: https://github.com/apache/iceberg/pull/6445#issuecomment-1355564692 Looks good to me! @Fokko, can you take a look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6444: Docs: add example of spark extension for identifier fields
rdblue commented on PR #6444: URL: https://github.com/apache/iceberg/pull/6444#issuecomment-1355565531 Thanks, @lvyanquan! This looks great. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6444: Docs: add example of spark extension for identifier fields
rdblue merged PR #6444: URL: https://github.com/apache/iceberg/pull/6444 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue merged pull request #6441: Run weekly JMH Benchmarks & visualize results
rdblue merged PR #6441: URL: https://github.com/apache/iceberg/pull/6441 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6441: Run weekly JMH Benchmarks & visualize results
rdblue commented on PR #6441: URL: https://github.com/apache/iceberg/pull/6441#issuecomment-1355567338 Thanks, @nastra! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a diff in pull request #6438: Python: Reduce the use of mock objects
rdblue commented on code in PR #6438: URL: https://github.com/apache/iceberg/pull/6438#discussion_r1051136493 ## python/pyiceberg/avro/reader.py: ## @@ -104,16 +104,22 @@ def _skip_map_array(decoder: BinaryDecoder, skip_entry: Callable[[], None]) -> N block_count = decoder.read_int() -@dataclass(frozen=True) class AvroStruct(StructProtocol): -_data: List[Union[Any, StructProtocol]] = dataclassfield() +_data: List[Union[Any, StructProtocol]] Review Comment: Is anything here specific to Avro? Or should this be a generic struct in a different place? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #6438: Python: Reduce the use of mock objects
rdblue commented on PR #6438: URL: https://github.com/apache/iceberg/pull/6438#issuecomment-1355572986 Looks good to me! I'm not merging in case you want to move/rename `AvroStruct` since it is really a generic class and not specific to Avro. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko opened a new pull request, #6446: Python: Support for UUID
Fokko opened a new pull request, #6446: URL: https://github.com/apache/iceberg/pull/6446 Closes #6434 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] pavibhai commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
pavibhai commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1051169885
##
orc/src/main/java/org/apache/iceberg/orc/FileIOFSUtil.java:
##
@@ -0,0 +1,164 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.orc;
+
+import java.io.FileNotFoundException;
+import java.io.IOException;
+import java.io.OutputStream;
+import java.net.URI;
+import org.apache.hadoop.fs.FSDataInputStream;
+import org.apache.hadoop.fs.FSDataOutputStream;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.permission.FsPermission;
+import org.apache.hadoop.util.Progressable;
+import org.apache.iceberg.hadoop.HadoopStreams;
+import org.apache.iceberg.io.InputFile;
+import org.apache.iceberg.io.OutputFile;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+
+public class FileIOFSUtil {
Review Comment:
Sure, done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] pavibhai commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
pavibhai commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1051170766
##
orc/src/test/java/org/apache/iceberg/orc/TestOrcDataWriter.java:
##
@@ -126,4 +135,116 @@ public void testDataWriter() throws IOException {
Assert.assertEquals("Written records should match", records,
writtenRecords);
}
+
+ @Test
+ public void testUsingFileIO() throws IOException {
+// Show that FileSystem access is not possible for the file we are
supplying as the scheme
+// dummy is not handled
+ProxyOutputFile outFile = new
ProxyOutputFile(Files.localOutput(temp.newFile()));
+Assertions.assertThatThrownBy(
+() -> HadoopOutputFile.fromPath(new Path(outFile.location()), new
Configuration()))
+.isInstanceOf(RuntimeIOException.class)
+.hasMessageStartingWith("Failed to get file system for path: dummy");
+
+// We are creating the proxy
+SortOrder sortOrder =
SortOrder.builderFor(SCHEMA).withOrderId(10).asc("id").build();
+
+DataWriter dataWriter =
+ORC.writeData(outFile)
+.schema(SCHEMA)
+.createWriterFunc(GenericOrcWriter::buildWriter)
+.overwrite()
+.withSpec(PartitionSpec.unpartitioned())
Review Comment:
yeah we need it, without it I get an error that `Cannot create data writer
without spec`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] pavibhai commented on a diff in pull request #6293: Added FileIO Support for ORC Reader and Writers
pavibhai commented on code in PR #6293:
URL: https://github.com/apache/iceberg/pull/6293#discussion_r1051170973
##
orc/src/main/java/org/apache/iceberg/orc/ORC.java:
##
@@ -789,7 +808,210 @@ static Reader newFileReader(InputFile file, Configuration
config) {
ReaderOptions readerOptions =
OrcFile.readerOptions(config).useUTCTimestamp(true);
if (file instanceof HadoopInputFile) {
readerOptions.filesystem(((HadoopInputFile) file).getFileSystem());
+} else {
Review Comment:
deleted
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] Fokko commented on a diff in pull request #6445: Python: Mock home and root folder when running `test_missing_uri`
Fokko commented on code in PR #6445:
URL: https://github.com/apache/iceberg/pull/6445#discussion_r1051172204
##
python/tests/utils/test_config.py:
##
@@ -39,7 +40,7 @@ def test_from_environment_variables_uppercase() -> None:
assert Config().get_catalog_config("PRODUCTION") == {"uri":
"https://service.io/api"}
-def test_from_configuration_files(tmp_path_factory) -> None: # type: ignore
+def test_from_configuration_files(tmp_path_factory: pytest.TempPathFactory) ->
None:
Review Comment:
Nice!
##
python/tests/cli/test_console.py:
##
@@ -134,14 +134,17 @@ def update_namespace_properties(
MOCK_ENVIRONMENT = {"PYICEBERG_CATALOG__PRODUCTION__URI":
"test://doesnotexist"}
-def test_missing_uri() -> None:
-runner = CliRunner()
-result = runner.invoke(run, ["list"])
-assert result.exit_code == 1
-assert (
-result.output
-== "URI missing, please provide using --uri, the config or environment
variable \nPYICEBERG_CATALOG__DEFAULT__URI\n"
-)
+def test_missing_uri(empty_home_dir_path: str) -> None:
Review Comment:
This looks good to me! I'd rather use the decorator
`@mock.patch.dict(os.environ, MOCK_ENVIRONMENT)` similar as the test below, but
I'm aware that we that we can't use the fixture on a global scope.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] szehon-ho commented on a diff in pull request #6344: Spark 3.3: Introduce the changelog iterator
szehon-ho commented on code in PR #6344:
URL: https://github.com/apache/iceberg/pull/6344#discussion_r1051211196
##
spark/v3.3/spark/src/main/java/org/apache/iceberg/spark/ChangelogIterator.java:
##
@@ -0,0 +1,195 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.spark;
+
+import java.io.Serializable;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Objects;
+import org.apache.iceberg.ChangelogOperation;
+import org.apache.iceberg.relocated.com.google.common.collect.Iterators;
+import org.apache.spark.sql.Row;
+import org.apache.spark.sql.RowFactory;
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow;
+import org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema;
+
+/**
+ * An iterator that transforms rows from changelog tables within a single
Spark task. It assumes
+ * that rows are sorted by identifier columns and change type.
+ *
+ * It removes the carry-over rows. Carry-over rows are unchanged rows in a
snapshot but showed as
+ * delete-rows and insert-rows in a changelog table due to the
copy-on-write(COW) mechanism. For
+ * example, there are row1 (id=1, data='a') and row2 (id=2, data='b') in a
data file, if we only
+ * delete row2, the COW will copy row1 to a new data file and delete the whole
old data file. The
+ * changelog table will have two delete-rows(row1 and row2), and one
insert-row(row1). Row1 is a
+ * carry-over row.
+ *
+ * The iterator marks the delete-row and insert-row to be the update-rows.
For example, these two
+ * rows
+ *
+ *
+ * (id=1, data='a', op='DELETE')
+ * (id=1, data='b', op='INSERT')
+ *
+ *
+ * will be marked as update-rows:
+ *
+ *
+ * (id=1, data='a', op='UPDATE_BEFORE')
+ * (id=1, data='b', op='UPDATE_AFTER')
+ *
+ */
+public class ChangelogIterator implements Iterator, Serializable {
+ private static final String DELETE = ChangelogOperation.DELETE.name();
+ private static final String INSERT = ChangelogOperation.INSERT.name();
+ private static final String UPDATE_BEFORE =
ChangelogOperation.UPDATE_BEFORE.name();
+ private static final String UPDATE_AFTER =
ChangelogOperation.UPDATE_AFTER.name();
+
+ private final Iterator rowIterator;
+ private final int changeTypeIndex;
+ private final List partitionIdx;
+
+ private Row cachedRow = null;
+
+ private ChangelogIterator(
+ Iterator rowIterator, int changeTypeIndex, List
partitionIdx) {
+this.rowIterator = rowIterator;
+this.changeTypeIndex = changeTypeIndex;
+this.partitionIdx = partitionIdx;
+ }
+
+ public static Iterator iterator(
+ Iterator rowIterator, int changeTypeIndex, List
partitionIdx) {
Review Comment:
can we still change name from partitionIdx to identifierFieldIdx?
Also a javadoc here on arguments will be useful.
##
spark/v3.3/spark/src/test/java/org/apache/iceberg/spark/SparkTestBase.java:
##
@@ -112,11 +112,11 @@ protected List sql(String query, Object...
args) {
return rowsToJava(rows);
}
- protected List rowsToJava(List rows) {
-return rows.stream().map(this::toJava).collect(Collectors.toList());
+ public static List rowsToJava(List rows) {
Review Comment:
Style: I feel its messy now to have this class now as inherited and a util
class. Especially some methods are changed to static and other methods are
not, even though they call the static ones.
What do you think? Maybe we can make a separate base class for the helper
methods like 'SparkTestHelperBase' and have both SparkTestBase and your test
inherit from it (to avoid changing all the tests)?
##
spark/v3.3/spark/src/main/java/org/apache/iceberg/spark/ChangelogIterator.java:
##
@@ -0,0 +1,195 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/lice
[GitHub] [iceberg] szehon-ho commented on a diff in pull request #6344: Spark 3.3: Introduce the changelog iterator
szehon-ho commented on code in PR #6344:
URL: https://github.com/apache/iceberg/pull/6344#discussion_r1051211196
##
spark/v3.3/spark/src/main/java/org/apache/iceberg/spark/ChangelogIterator.java:
##
@@ -0,0 +1,195 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.spark;
+
+import java.io.Serializable;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Objects;
+import org.apache.iceberg.ChangelogOperation;
+import org.apache.iceberg.relocated.com.google.common.collect.Iterators;
+import org.apache.spark.sql.Row;
+import org.apache.spark.sql.RowFactory;
+import org.apache.spark.sql.catalyst.expressions.GenericInternalRow;
+import org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema;
+
+/**
+ * An iterator that transforms rows from changelog tables within a single
Spark task. It assumes
+ * that rows are sorted by identifier columns and change type.
+ *
+ * It removes the carry-over rows. Carry-over rows are unchanged rows in a
snapshot but showed as
+ * delete-rows and insert-rows in a changelog table due to the
copy-on-write(COW) mechanism. For
+ * example, there are row1 (id=1, data='a') and row2 (id=2, data='b') in a
data file, if we only
+ * delete row2, the COW will copy row1 to a new data file and delete the whole
old data file. The
+ * changelog table will have two delete-rows(row1 and row2), and one
insert-row(row1). Row1 is a
+ * carry-over row.
+ *
+ * The iterator marks the delete-row and insert-row to be the update-rows.
For example, these two
+ * rows
+ *
+ *
+ * (id=1, data='a', op='DELETE')
+ * (id=1, data='b', op='INSERT')
+ *
+ *
+ * will be marked as update-rows:
+ *
+ *
+ * (id=1, data='a', op='UPDATE_BEFORE')
+ * (id=1, data='b', op='UPDATE_AFTER')
+ *
+ */
+public class ChangelogIterator implements Iterator, Serializable {
+ private static final String DELETE = ChangelogOperation.DELETE.name();
+ private static final String INSERT = ChangelogOperation.INSERT.name();
+ private static final String UPDATE_BEFORE =
ChangelogOperation.UPDATE_BEFORE.name();
+ private static final String UPDATE_AFTER =
ChangelogOperation.UPDATE_AFTER.name();
+
+ private final Iterator rowIterator;
+ private final int changeTypeIndex;
+ private final List partitionIdx;
+
+ private Row cachedRow = null;
+
+ private ChangelogIterator(
+ Iterator rowIterator, int changeTypeIndex, List
partitionIdx) {
+this.rowIterator = rowIterator;
+this.changeTypeIndex = changeTypeIndex;
+this.partitionIdx = partitionIdx;
+ }
+
+ public static Iterator iterator(
+ Iterator rowIterator, int changeTypeIndex, List
partitionIdx) {
Review Comment:
can we still change name from partitionIdx to identifierFieldIdx? Be better
not to mention partition at all to avoid confusion with real partition fields.
Also a javadoc here on arguments will be useful.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051230270
##
build.gradle:
##
@@ -696,6 +696,26 @@ project(':iceberg-dell') {
}
}
+project(':iceberg-snowflake') {
+ test {
+useJUnitPlatform()
+ }
+
+ dependencies {
+implementation project(':iceberg-core')
+implementation project(':iceberg-common')
+implementation project(path: ':iceberg-bundled-guava', configuration:
'shadow')
+implementation project(':iceberg-aws')
+implementation "com.fasterxml.jackson.core:jackson-databind"
+implementation "com.fasterxml.jackson.core:jackson-core"
+implementation "commons-dbutils:commons-dbutils:1.7"
+
+runtimeOnly("net.snowflake:snowflake-jdbc:3.13.22")
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051230626
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
+ this.catalogName = name;
+}
+
+if (snowflakeClient == null) {
+ String uri = properties.get(CatalogProperties.URI);
+ Preconditions.checkNotNull(uri, "JDBC connection URI is required");
+
+ try {
+// We'll ensure the expected JDBC driver implementation class is
initialized through
+// reflection
+// regardless of which classloader ends up using this
JdbcSnowflakeClient, but we'll only
+// warn if the expected driver fails to load, since users may use
repackaged or custom
+// JDBC drivers for Snowflake communcation.
+Class.forName(JdbcSnowflakeClient.EXPECTED_JDBC_IMPL);
+ } catch (ClassNotFoundException cnfe) {
+LOG.warn(
+"Failed to load expected JDBC SnowflakeDriver - if queries fail by
failing"
++ " to find a suitable driver for jdbc:snowflak
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051230895
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
Review Comment:
Done. Much cleaner, thanks for the suggestion!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051231396
##
snowflake/src/test/java/org/apache/iceberg/snowflake/SnowflakeCatalogTest.java:
##
@@ -0,0 +1,231 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableMetadata;
+import org.apache.iceberg.TableMetadataParser;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Test;
+
+public class SnowflakeCatalogTest {
+
+ static final String TEST_CATALOG_NAME = "slushLog";
+ private SnowflakeCatalog catalog;
+
+ @Before
+ public void before() {
+catalog = new SnowflakeCatalog();
+
+FakeSnowflakeClient client = new FakeSnowflakeClient();
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_1",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab1/metadata/v3.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_2",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab2/metadata/v1.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_3",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab3/metadata/v334.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_4",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab4/metadata/v323.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_3",
+"TAB_5",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab5/metadata/v793.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_4",
+"TAB_6",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab6/metadata/v123.metadata.json\",\"status\":\"success\"}"));
+
+catalog.setSnowflakeClient(client);
+
+InMemoryFileIO fakeFileIO = new InMemoryFileIO();
+
+Schema schema =
+new Schema(
+Types.NestedField.required(1, "x", Types.StringType.get(),
"comment1"),
+Types.NestedField.required(2, "y", Types.StringType.get(),
"comment2"));
+PartitionSpec partitionSpec =
+
PartitionSpec.builderFor(schema).identity("x").withSpecId(1000).build();
+fakeFileIO.addFile(
+"s3://tab1/metadata/v3.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "s3://tab1/", ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab3/metadata/v334.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema,
+partitionSpec,
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab1/",
+ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+"gs://tab5/metadata/v793.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "gs://tab5/", ImmutableMap.of()))
+.getBytes());
+
+catalog.setFileI
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051241597
##
snowflake/src/test/java/org/apache/iceberg/snowflake/SnowflakeCatalogTest.java:
##
@@ -0,0 +1,231 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableMetadata;
+import org.apache.iceberg.TableMetadataParser;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Test;
+
+public class SnowflakeCatalogTest {
+
+ static final String TEST_CATALOG_NAME = "slushLog";
+ private SnowflakeCatalog catalog;
+
+ @Before
+ public void before() {
+catalog = new SnowflakeCatalog();
+
+FakeSnowflakeClient client = new FakeSnowflakeClient();
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_1",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab1/metadata/v3.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_2",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab2/metadata/v1.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_3",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab3/metadata/v334.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_4",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab4/metadata/v323.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_3",
+"TAB_5",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab5/metadata/v793.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_4",
+"TAB_6",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab6/metadata/v123.metadata.json\",\"status\":\"success\"}"));
+
+catalog.setSnowflakeClient(client);
+
+InMemoryFileIO fakeFileIO = new InMemoryFileIO();
+
+Schema schema =
+new Schema(
+Types.NestedField.required(1, "x", Types.StringType.get(),
"comment1"),
+Types.NestedField.required(2, "y", Types.StringType.get(),
"comment2"));
+PartitionSpec partitionSpec =
+
PartitionSpec.builderFor(schema).identity("x").withSpecId(1000).build();
+fakeFileIO.addFile(
+"s3://tab1/metadata/v3.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "s3://tab1/", ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab3/metadata/v334.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema,
+partitionSpec,
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab1/",
+ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+"gs://tab5/metadata/v793.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "gs://tab5/", ImmutableMap.of()))
+.getBytes());
+
+catalog.setFileI
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051241705
##
snowflake/src/test/java/org/apache/iceberg/snowflake/SnowflakeCatalogTest.java:
##
@@ -0,0 +1,231 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableMetadata;
+import org.apache.iceberg.TableMetadataParser;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Test;
+
+public class SnowflakeCatalogTest {
+
+ static final String TEST_CATALOG_NAME = "slushLog";
+ private SnowflakeCatalog catalog;
+
+ @Before
+ public void before() {
+catalog = new SnowflakeCatalog();
+
+FakeSnowflakeClient client = new FakeSnowflakeClient();
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_1",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab1/metadata/v3.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_2",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab2/metadata/v1.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_3",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab3/metadata/v334.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_4",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab4/metadata/v323.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_3",
+"TAB_5",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab5/metadata/v793.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_4",
+"TAB_6",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab6/metadata/v123.metadata.json\",\"status\":\"success\"}"));
+
+catalog.setSnowflakeClient(client);
+
+InMemoryFileIO fakeFileIO = new InMemoryFileIO();
+
+Schema schema =
+new Schema(
+Types.NestedField.required(1, "x", Types.StringType.get(),
"comment1"),
+Types.NestedField.required(2, "y", Types.StringType.get(),
"comment2"));
+PartitionSpec partitionSpec =
+
PartitionSpec.builderFor(schema).identity("x").withSpecId(1000).build();
+fakeFileIO.addFile(
+"s3://tab1/metadata/v3.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "s3://tab1/", ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab3/metadata/v334.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema,
+partitionSpec,
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab1/",
+ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+"gs://tab5/metadata/v793.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "gs://tab5/", ImmutableMap.of()))
+.getBytes());
+
+catalog.setFileI
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051244552
##
snowflake/src/main/java/org/apache/iceberg/snowflake/JdbcSnowflakeClient.java:
##
@@ -0,0 +1,163 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.sql.SQLException;
+import java.util.List;
+import org.apache.commons.dbutils.QueryRunner;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import org.apache.iceberg.jdbc.UncheckedInterruptedException;
+import org.apache.iceberg.jdbc.UncheckedSQLException;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * This implementation of SnowflakeClient builds on top of Snowflake's JDBC
driver to interact with
+ * Snowflake's Iceberg-aware resource model. Despite using JDBC libraries, the
resource model is
+ * derived from Snowflake's own first-class support for Iceberg tables as
opposed to using an opaque
+ * JDBC layer to store Iceberg metadata itself in an Iceberg-agnostic database.
+ *
+ * This thus differs from the JdbcCatalog in that Snowflake's service
provides the source of
+ * truth of Iceberg metadata, rather than serving as a storage layer for a
client-defined Iceberg
+ * resource model.
+ */
+public class JdbcSnowflakeClient implements SnowflakeClient {
+ public static final String EXPECTED_JDBC_IMPL =
"net.snowflake.client.jdbc.SnowflakeDriver";
+
+ private static final Logger LOG =
LoggerFactory.getLogger(JdbcSnowflakeClient.class);
+ private final JdbcClientPool connectionPool;
+ private QueryRunner queryRunner = new QueryRunner(true);
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051245397
##
snowflake/src/main/java/org/apache/iceberg/snowflake/JdbcSnowflakeClient.java:
##
@@ -0,0 +1,163 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.sql.SQLException;
+import java.util.List;
+import org.apache.commons.dbutils.QueryRunner;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import org.apache.iceberg.jdbc.UncheckedInterruptedException;
+import org.apache.iceberg.jdbc.UncheckedSQLException;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * This implementation of SnowflakeClient builds on top of Snowflake's JDBC
driver to interact with
+ * Snowflake's Iceberg-aware resource model. Despite using JDBC libraries, the
resource model is
+ * derived from Snowflake's own first-class support for Iceberg tables as
opposed to using an opaque
+ * JDBC layer to store Iceberg metadata itself in an Iceberg-agnostic database.
+ *
+ * This thus differs from the JdbcCatalog in that Snowflake's service
provides the source of
+ * truth of Iceberg metadata, rather than serving as a storage layer for a
client-defined Iceberg
+ * resource model.
+ */
+public class JdbcSnowflakeClient implements SnowflakeClient {
+ public static final String EXPECTED_JDBC_IMPL =
"net.snowflake.client.jdbc.SnowflakeDriver";
+
+ private static final Logger LOG =
LoggerFactory.getLogger(JdbcSnowflakeClient.class);
+ private final JdbcClientPool connectionPool;
+ private QueryRunner queryRunner = new QueryRunner(true);
+
+ JdbcSnowflakeClient(JdbcClientPool conn) {
+connectionPool = conn;
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051251362
##
snowflake/src/main/java/org/apache/iceberg/snowflake/JdbcSnowflakeClient.java:
##
@@ -0,0 +1,163 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.sql.SQLException;
+import java.util.List;
+import org.apache.commons.dbutils.QueryRunner;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import org.apache.iceberg.jdbc.UncheckedInterruptedException;
+import org.apache.iceberg.jdbc.UncheckedSQLException;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * This implementation of SnowflakeClient builds on top of Snowflake's JDBC
driver to interact with
+ * Snowflake's Iceberg-aware resource model. Despite using JDBC libraries, the
resource model is
+ * derived from Snowflake's own first-class support for Iceberg tables as
opposed to using an opaque
+ * JDBC layer to store Iceberg metadata itself in an Iceberg-agnostic database.
+ *
+ * This thus differs from the JdbcCatalog in that Snowflake's service
provides the source of
+ * truth of Iceberg metadata, rather than serving as a storage layer for a
client-defined Iceberg
+ * resource model.
+ */
+public class JdbcSnowflakeClient implements SnowflakeClient {
+ public static final String EXPECTED_JDBC_IMPL =
"net.snowflake.client.jdbc.SnowflakeDriver";
+
+ private static final Logger LOG =
LoggerFactory.getLogger(JdbcSnowflakeClient.class);
+ private final JdbcClientPool connectionPool;
+ private QueryRunner queryRunner = new QueryRunner(true);
+
+ JdbcSnowflakeClient(JdbcClientPool conn) {
+connectionPool = conn;
+ }
+
+ @VisibleForTesting
+ void setQueryRunner(QueryRunner queryRunner) {
+this.queryRunner = queryRunner;
+ }
+
+ @Override
+ public List listSchemas(Namespace namespace) {
+StringBuilder baseQuery = new StringBuilder("SHOW SCHEMAS");
+Object[] queryParams = null;
+if (namespace == null || namespace.isEmpty()) {
+ // for empty or null namespace search for all schemas at account level
where the user
+ // has access to list.
+ baseQuery.append(" IN ACCOUNT");
+} else {
+ // otherwise restrict listing of schema within the database.
+ baseQuery.append(" IN DATABASE IDENTIFIER(?)");
+ queryParams = new Object[]
{namespace.level(SnowflakeResources.NAMESPACE_DB_LEVEL - 1)};
+}
+
+final String finalQuery = baseQuery.toString();
+final Object[] finalQueryParams = queryParams;
+List schemas;
+try {
+ schemas =
+ connectionPool.run(
+ conn ->
+ queryRunner.query(
+ conn, finalQuery, SnowflakeSchema.createHandler(),
finalQueryParams));
+} catch (SQLException e) {
+ throw new UncheckedSQLException(
+ e,
+ "Failed to list schemas for namespace %s",
+ namespace != null ? namespace.toString() : "");
+} catch (InterruptedException e) {
+ throw new UncheckedInterruptedException(e, "Interrupted while listing
schemas");
+}
+return schemas;
+ }
+
+ @Override
+ public List listIcebergTables(Namespace namespace) {
+StringBuilder baseQuery = new StringBuilder("SHOW ICEBERG TABLES");
+Object[] queryParams = null;
+if (namespace.length() == SnowflakeResources.MAX_NAMESPACE_DEPTH) {
+ // For two level namespace, search for iceberg tables within the given
schema.
+ baseQuery.append(" IN SCHEMA IDENTIFIER(?)");
+ queryParams =
+ new Object[] {
+String.format(
+"%s.%s",
+namespace.level(SnowflakeResources.NAMESPACE_DB_LEVEL - 1),
+namespace.level(SnowflakeResources.NAMESPACE_SCHEMA_LEVEL - 1))
+ };
+} else if (namespace.
[GitHub] [iceberg] szehon-ho commented on a diff in pull request #6365: Core: Add position deletes metadata table
szehon-ho commented on code in PR #6365: URL: https://github.com/apache/iceberg/pull/6365#discussion_r1051251356 ## core/src/main/java/org/apache/iceberg/AbstractTableScan.java: ## @@ -0,0 +1,173 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, + * software distributed under the License is distributed on an + * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY + * KIND, either express or implied. See the License for the + * specific language governing permissions and limitations + * under the License. + */ +package org.apache.iceberg; + +import java.util.List; +import java.util.Map; +import java.util.stream.Collectors; +import org.apache.iceberg.events.Listeners; +import org.apache.iceberg.events.ScanEvent; +import org.apache.iceberg.expressions.ExpressionUtil; +import org.apache.iceberg.io.CloseableIterable; +import org.apache.iceberg.metrics.DefaultMetricsContext; +import org.apache.iceberg.metrics.ImmutableScanReport; +import org.apache.iceberg.metrics.ScanMetrics; +import org.apache.iceberg.metrics.ScanMetricsResult; +import org.apache.iceberg.metrics.ScanReport; +import org.apache.iceberg.metrics.Timer; +import org.apache.iceberg.relocated.com.google.common.base.MoreObjects; +import org.apache.iceberg.relocated.com.google.common.base.Preconditions; +import org.apache.iceberg.relocated.com.google.common.collect.Lists; +import org.apache.iceberg.relocated.com.google.common.collect.Maps; +import org.apache.iceberg.types.TypeUtil; +import org.apache.iceberg.util.DateTimeUtil; +import org.apache.iceberg.util.SnapshotUtil; +import org.apache.iceberg.util.TableScanUtil; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; + +public abstract class AbstractTableScan> Review Comment: So this class is the parent of BaseTableScan and PositionDeleteTableScan and most of the logic is moved from BaseTableScan to share it. Im not too sure what to do about the names. At this point BaseTableScan is more like an empty wrapper that serves to parameterize T with FileScanTask. Note: Im not happy with the bounds of T here (ideally can be T extends ContentScanTask). But as PositionDeleteScanTask has to implement BatchScan , that would conflict with BatchScan's hard coded "ScanTask" parameter of Scan. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051262362
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
+ this.catalogName = name;
+}
+
+if (snowflakeClient == null) {
+ String uri = properties.get(CatalogProperties.URI);
+ Preconditions.checkNotNull(uri, "JDBC connection URI is required");
+
+ try {
+// We'll ensure the expected JDBC driver implementation class is
initialized through
+// reflection
+// regardless of which classloader ends up using this
JdbcSnowflakeClient, but we'll only
+// warn if the expected driver fails to load, since users may use
repackaged or custom
+// JDBC drivers for Snowflake communcation.
+Class.forName(JdbcSnowflakeClient.EXPECTED_JDBC_IMPL);
+ } catch (ClassNotFoundException cnfe) {
+LOG.warn(
+"Failed to load expected JDBC SnowflakeDriver - if queries fail by
failing"
++ " to find a suitable driver for jdbc:snowflak
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051264532
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
+ this.catalogName = name;
+}
+
+if (snowflakeClient == null) {
+ String uri = properties.get(CatalogProperties.URI);
+ Preconditions.checkNotNull(uri, "JDBC connection URI is required");
+
+ try {
+// We'll ensure the expected JDBC driver implementation class is
initialized through
+// reflection
+// regardless of which classloader ends up using this
JdbcSnowflakeClient, but we'll only
+// warn if the expected driver fails to load, since users may use
repackaged or custom
+// JDBC drivers for Snowflake communcation.
+Class.forName(JdbcSnowflakeClient.EXPECTED_JDBC_IMPL);
+ } catch (ClassNotFoundException cnfe) {
+LOG.warn(
+"Failed to load expected JDBC SnowflakeDriver - if queries fail by
failing"
++ " to find a suitable driver for jdbc:snowflak
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051265807
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeClient.java:
##
@@ -0,0 +1,44 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+
+/**
+ * This interface abstracts out the underlying communication protocols for
contacting Snowflake to
+ * obtain the various resource representations defined under "entities".
Classes using this
+ * interface should minimize assumptions about whether an underlying client
uses e.g. REST, JDBC or
+ * other underlying libraries/protocols.
+ */
+public interface SnowflakeClient extends Closeable {
+ List listSchemas(Namespace namespace);
+
+ List listIcebergTables(Namespace namespace);
+
+ SnowflakeTableMetadata getTableMetadata(TableIdentifier tableIdentifier);
+
+ @Override
Review Comment:
Looks like now with CloseableGroup it's probably not worth worrying about
the exception in the signature; went ahead and removed this override.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051267959
##
snowflake/src/test/java/org/apache/iceberg/snowflake/SnowflakeCatalogTest.java:
##
@@ -0,0 +1,231 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableMetadata;
+import org.apache.iceberg.TableMetadataParser;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Test;
+
+public class SnowflakeCatalogTest {
+
+ static final String TEST_CATALOG_NAME = "slushLog";
+ private SnowflakeCatalog catalog;
+
+ @Before
+ public void before() {
+catalog = new SnowflakeCatalog();
+
+FakeSnowflakeClient client = new FakeSnowflakeClient();
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_1",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab1/metadata/v3.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_2",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab2/metadata/v1.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_3",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab3/metadata/v334.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_4",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab4/metadata/v323.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_3",
+"TAB_5",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab5/metadata/v793.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_4",
+"TAB_6",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"gcs://tab6/metadata/v123.metadata.json\",\"status\":\"success\"}"));
+
+catalog.setSnowflakeClient(client);
+
+InMemoryFileIO fakeFileIO = new InMemoryFileIO();
+
+Schema schema =
+new Schema(
+Types.NestedField.required(1, "x", Types.StringType.get(),
"comment1"),
+Types.NestedField.required(2, "y", Types.StringType.get(),
"comment2"));
+PartitionSpec partitionSpec =
+
PartitionSpec.builderFor(schema).identity("x").withSpecId(1000).build();
+fakeFileIO.addFile(
+"s3://tab1/metadata/v3.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "s3://tab1/", ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab3/metadata/v334.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema,
+partitionSpec,
+
"wasbs://mycontai...@myaccount.blob.core.windows.net/tab1/",
+ImmutableMap.of()))
+.getBytes());
+fakeFileIO.addFile(
+"gs://tab5/metadata/v793.metadata.json",
+TableMetadataParser.toJson(
+TableMetadata.newTableMetadata(
+schema, partitionSpec, "gs://tab5/", ImmutableMap.of()))
+.getBytes());
+
+catalog.setFileI
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051272184
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
+ this.catalogName = name;
+}
+
+if (snowflakeClient == null) {
+ String uri = properties.get(CatalogProperties.URI);
+ Preconditions.checkNotNull(uri, "JDBC connection URI is required");
+
+ try {
+// We'll ensure the expected JDBC driver implementation class is
initialized through
+// reflection
+// regardless of which classloader ends up using this
JdbcSnowflakeClient, but we'll only
+// warn if the expected driver fails to load, since users may use
repackaged or custom
+// JDBC drivers for Snowflake communcation.
+Class.forName(JdbcSnowflakeClient.EXPECTED_JDBC_IMPL);
+ } catch (ClassNotFoundException cnfe) {
+LOG.warn(
+"Failed to load expected JDBC SnowflakeDriver - if queries fail by
failing"
++ " to find a suitable driver for jdbc:snowflak
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051274163
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeCatalog.java:
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.io.Closeable;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.stream.Collectors;
+import org.apache.iceberg.BaseMetastoreCatalog;
+import org.apache.iceberg.CatalogProperties;
+import org.apache.iceberg.CatalogUtil;
+import org.apache.iceberg.TableOperations;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.SupportsNamespaces;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.exceptions.NoSuchNamespaceException;
+import org.apache.iceberg.hadoop.Configurable;
+import org.apache.iceberg.io.FileIO;
+import org.apache.iceberg.jdbc.JdbcClientPool;
+import
org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeSchema;
+import org.apache.iceberg.snowflake.entities.SnowflakeTable;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class SnowflakeCatalog extends BaseMetastoreCatalog
+implements Closeable, SupportsNamespaces, Configurable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(SnowflakeCatalog.class);
+
+ private Object conf;
+ private String catalogName = SnowflakeResources.DEFAULT_CATALOG_NAME;
+ private Map catalogProperties = null;
+ private FileIO fileIO;
+ private SnowflakeClient snowflakeClient;
+
+ public SnowflakeCatalog() {}
+
+ @VisibleForTesting
+ void setSnowflakeClient(SnowflakeClient snowflakeClient) {
+this.snowflakeClient = snowflakeClient;
+ }
+
+ @VisibleForTesting
+ void setFileIO(FileIO fileIO) {
+this.fileIO = fileIO;
+ }
+
+ @Override
+ public List listTables(Namespace namespace) {
+LOG.debug("listTables with namespace: {}", namespace);
+Preconditions.checkArgument(
+namespace.length() <= SnowflakeResources.MAX_NAMESPACE_DEPTH,
+"Snowflake doesn't support more than %s levels of namespace, got %s",
+SnowflakeResources.MAX_NAMESPACE_DEPTH,
+namespace);
+
+List sfTables =
snowflakeClient.listIcebergTables(namespace);
+
+return sfTables.stream()
+.map(
+table ->
+TableIdentifier.of(table.getDatabase(), table.getSchemaName(),
table.getName()))
+.collect(Collectors.toList());
+ }
+
+ @Override
+ public boolean dropTable(TableIdentifier identifier, boolean purge) {
+throw new UnsupportedOperationException(
+String.format("dropTable not supported; attempted for table '%s'",
identifier));
+ }
+
+ @Override
+ public void renameTable(TableIdentifier from, TableIdentifier to) {
+throw new UnsupportedOperationException(
+String.format("renameTable not supported; attempted from '%s' to
'%s'", from, to));
+ }
+
+ @Override
+ public void initialize(String name, Map properties) {
+catalogProperties = properties;
+
+if (name != null) {
+ this.catalogName = name;
+}
+
+if (snowflakeClient == null) {
+ String uri = properties.get(CatalogProperties.URI);
+ Preconditions.checkNotNull(uri, "JDBC connection URI is required");
+
+ try {
+// We'll ensure the expected JDBC driver implementation class is
initialized through
+// reflection
+// regardless of which classloader ends up using this
JdbcSnowflakeClient, but we'll only
+// warn if the expected driver fails to load, since users may use
repackaged or custom
+// JDBC drivers for Snowflake communcation.
+Class.forName(JdbcSnowflakeClient.EXPECTED_JDBC_IMPL);
+ } catch (ClassNotFoundException cnfe) {
+LOG.warn(
+"Failed to load expected JDBC SnowflakeDriver - if queries fail by
failing"
++ " to find a suitable driver for jdbc:snowflak
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051274675
##
snowflake/src/main/java/org/apache/iceberg/snowflake/SnowflakeResources.java:
##
@@ -0,0 +1,29 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+final class SnowflakeResources {
Review Comment:
Yeah, this is a bit awkward at the moment just because we ideally wanted to
create a clean `SnowflakeClient` abstraction layer that can be
well-encapsulated from `SnowflakeCatalog` and Iceberg-specific business logic,
but indeed the processing of Namespace levels unfortunately leaks into both.
I'll see if refactoring out a SnowflakeIdentifier can move all
Namespace-processing stuff into one place and hopefully also make this
container class unnecessary.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on a diff in pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on code in PR #6428:
URL: https://github.com/apache/iceberg/pull/6428#discussion_r1051274939
##
snowflake/src/main/java/org/apache/iceberg/snowflake/entities/SnowflakeTable.java:
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake.entities;
+
+import java.util.List;
+import org.apache.commons.dbutils.ResultSetHandler;
+import org.apache.iceberg.relocated.com.google.common.base.Objects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class SnowflakeTable {
+ private String databaseName;
+ private String schemaName;
+ private String name;
+
+ public SnowflakeTable(String databaseName, String schemaName, String name) {
Review Comment:
Yeah, as @manisin mentions we'll ideally maintain an abstraction layer to
keep the underlying client impl(s) clean from Namespace-level-processing stuff,
but agree the current entity layout seems a bit verbose. I'll see if we can
squish into a SnowflakeIdentifier instead.
##
snowflake/src/test/java/org/apache/iceberg/snowflake/SnowflakeCatalogTest.java:
##
@@ -0,0 +1,231 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.snowflake;
+
+import java.util.List;
+import java.util.Map;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableMetadata;
+import org.apache.iceberg.TableMetadataParser;
+import org.apache.iceberg.catalog.Namespace;
+import org.apache.iceberg.catalog.TableIdentifier;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.snowflake.entities.SnowflakeTableMetadata;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Test;
+
+public class SnowflakeCatalogTest {
+
+ static final String TEST_CATALOG_NAME = "slushLog";
+ private SnowflakeCatalog catalog;
+
+ @Before
+ public void before() {
+catalog = new SnowflakeCatalog();
+
+FakeSnowflakeClient client = new FakeSnowflakeClient();
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_1",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab1/metadata/v3.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_1",
+"SCHEMA_1",
+"TAB_2",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"s3://tab2/metadata/v1.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_3",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab3/metadata/v334.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_2",
+"SCHEMA_2",
+"TAB_4",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\":\"azure://myaccount.blob.core.windows.net/mycontainer/tab4/metadata/v323.metadata.json\",\"status\":\"success\"}"));
+client.addTable(
+"DB_3",
+"SCHEMA_3",
+"TAB_5",
+SnowflakeTableMetadata.parseJson(
+
"{\"metadataLocation\"
[GitHub] [iceberg] xwmr-max commented on pull request #6440: Flink: Support Look-up Function
xwmr-max commented on PR #6440: URL: https://github.com/apache/iceberg/pull/6440#issuecomment-1355946472 cc @stevenzwu @hililiwei -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] dennishuo commented on pull request #6428: Add new SnowflakeCatalog implementation to enable directly using Snowflake-managed Iceberg tables
dennishuo commented on PR #6428: URL: https://github.com/apache/iceberg/pull/6428#issuecomment-1356015002 @nastra Thanks for the thorough review and suggestions! Finished applying all your suggestions, including fully converting to `assertj`/`Assertions` and refactoring out the Namespace<->SnowflakeIdentifier parsing to better encapsulate all the argument-checking/parsing into one place. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] pvary commented on issue #6370: What is the purpose of Hive Lock ?
pvary commented on issue #6370: URL: https://github.com/apache/iceberg/issues/6370#issuecomment-1356061017 @InvisibleProgrammer, @TuroczyX: any news about the atomic lock? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rubenvdg commented on a diff in pull request #6445: Python: Mock home and root folder when running `test_missing_uri`
rubenvdg commented on code in PR #6445:
URL: https://github.com/apache/iceberg/pull/6445#discussion_r1051331332
##
python/tests/cli/test_console.py:
##
@@ -134,14 +134,17 @@ def update_namespace_properties(
MOCK_ENVIRONMENT = {"PYICEBERG_CATALOG__PRODUCTION__URI":
"test://doesnotexist"}
-def test_missing_uri() -> None:
-runner = CliRunner()
-result = runner.invoke(run, ["list"])
-assert result.exit_code == 1
-assert (
-result.output
-== "URI missing, please provide using --uri, the config or environment
variable \nPYICEBERG_CATALOG__DEFAULT__URI\n"
-)
+def test_missing_uri(empty_home_dir_path: str) -> None:
Review Comment:
Yeah me too. If you're adamant about it, could do the following, but I'd say
it's a pretty terrible workaround
```
def test_missing_uri(empty_home_dir_path)
@mock.patch.dict(os.environ, {"HOME": empty_home_dir_path})
def _test_missing_uri():
...
_test_missing_uri()
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rubenvdg commented on a diff in pull request #6445: Python: Mock home and root folder when running `test_missing_uri`
rubenvdg commented on code in PR #6445:
URL: https://github.com/apache/iceberg/pull/6445#discussion_r1051332065
##
python/tests/cli/test_console.py:
##
@@ -134,14 +134,17 @@ def update_namespace_properties(
MOCK_ENVIRONMENT = {"PYICEBERG_CATALOG__PRODUCTION__URI":
"test://doesnotexist"}
-def test_missing_uri() -> None:
-runner = CliRunner()
-result = runner.invoke(run, ["list"])
-assert result.exit_code == 1
-assert (
-result.output
-== "URI missing, please provide using --uri, the config or environment
variable \nPYICEBERG_CATALOG__DEFAULT__URI\n"
-)
+def test_missing_uri(empty_home_dir_path: str) -> None:
Review Comment:
Alternatively, we could do something like this in `conftest.py`:
```
def make_temporary_home_folder(tmp_path_factory) -> None:
home_path = str(tmp_path_factory.mktemp("home"))
os.environ["TMP_HOME_PATH"] = home_path
```
and then in the test
```
@mock.patch.dict(os.environ, {"HOME": os.environ["TMP_HOME_PATH"]})
def test_missing_uri():
...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] rubenvdg commented on a diff in pull request #6445: Python: Mock home and root folder when running `test_missing_uri`
rubenvdg commented on code in PR #6445:
URL: https://github.com/apache/iceberg/pull/6445#discussion_r1051331332
##
python/tests/cli/test_console.py:
##
@@ -134,14 +134,17 @@ def update_namespace_properties(
MOCK_ENVIRONMENT = {"PYICEBERG_CATALOG__PRODUCTION__URI":
"test://doesnotexist"}
-def test_missing_uri() -> None:
-runner = CliRunner()
-result = runner.invoke(run, ["list"])
-assert result.exit_code == 1
-assert (
-result.output
-== "URI missing, please provide using --uri, the config or environment
variable \nPYICEBERG_CATALOG__DEFAULT__URI\n"
-)
+def test_missing_uri(empty_home_dir_path: str) -> None:
Review Comment:
Yeah me too. If you're adamant about it, could do the following, but I'd say
it's a pretty terrible workaround
```
def test_missing_uri(empty_home_dir_path)
@mock.patch.dict(os.environ, {"HOME": empty_home_dir_path})
def _test_missing_uri():
...
_test_missing_uri()
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org
For additional commands, e-mail: issues-h...@iceberg.apache.org
[GitHub] [iceberg] shardulm94 commented on issue #6224: Spark: regression / query failure with Iceberg 1.0.0 and UNION
shardulm94 commented on issue #6224: URL: https://github.com/apache/iceberg/issues/6224#issuecomment-1356083642 Hey @maximethebault! Thanks for the report. I investigated this and found that that it is actually a bug in Spark 3.3.1+. I have created [SPARK-41557](https://issues.apache.org/jira/browse/SPARK-41557) against the Spark project to track this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: issues-unsubscr...@iceberg.apache.org For additional commands, e-mail: issues-h...@iceberg.apache.org