Fokko commented on code in PR #6437:
URL: https://github.com/apache/iceberg/pull/6437#discussion_r1050587798
##########
python/pyiceberg/io/pyarrow.py:
##########
@@ -437,3 +457,103 @@ def visit_or(self, left_result: pc.Expression,
right_result: pc.Expression) -> p
def expression_to_pyarrow(expr: BooleanExpression) -> pc.Expression:
return boolean_expression_visit(expr, _ConvertToArrowExpression())
+
+
+class _ConstructFinalSchema(SchemaVisitor[pa.ChunkedArray]):
+ file_schema: Schema
+ table: pa.Table
+
+ def __init__(self, file_schema: Schema, table: pa.Table):
+ self.file_schema = file_schema
+ self.table = table
+
+ def schema(self, schema: Schema, struct_result: List[pa.ChunkedArray]) ->
pa.Table:
+ return pa.table(struct_result, schema=schema_to_pyarrow(schema))
+
+ def struct(self, _: StructType, field_results: List[pa.ChunkedArray]) ->
List[pa.ChunkedArray]:
+ return field_results
+
+ def field(self, field: NestedField, _: pa.ChunkedArray) -> pa.ChunkedArray:
+ column_name = self.file_schema.find_column_name(field.field_id)
+
+ if column_name:
+ column_idx = self.table.schema.get_field_index(column_name)
+ else:
+ column_idx = -1
+
+ expected_arrow_type = schema_to_pyarrow(field.field_type)
+
+ # The idx will be -1 when the column can't be found
+ if column_idx >= 0:
+ column_field: pa.Field = self.table.schema[column_idx]
+ column_arrow_type: pa.DataType = column_field.type
+ column_data: pa.ChunkedArray = self.table[column_idx]
+
+ # In case of schema evolution
+ if column_arrow_type != expected_arrow_type:
+ column_data = column_data.cast(expected_arrow_type)
+ else:
+ import numpy as np
+
+ column_data = pa.array(np.full(shape=len(self.table),
fill_value=None), type=expected_arrow_type)
+ return column_data
+
+ def list(self, _: ListType, element_result: pa.ChunkedArray) ->
pa.ChunkedArray:
+ pass
+
+ def map(self, _: MapType, key_result: pa.ChunkedArray, value_result:
pa.ChunkedArray) -> pa.DataType:
+ pass
+
+ def primitive(self, primitive: PrimitiveType) -> pa.ChunkedArray:
+ pass
+
+
+def to_final_schema(final_schema: Schema, schema: Schema, table: pa.Table) ->
pa.Table:
+ return visit(final_schema, _ConstructFinalSchema(schema, table))
+
+
+def project_table(
+ files: Iterable["FileScanTask"], table: "Table", row_filter:
BooleanExpression, projected_schema: Schema, case_sensitive: bool
+) -> pa.Table:
+ if isinstance(table.io, PyArrowFileIO):
+ scheme, path = PyArrowFileIO.parse_location(table.location())
+ fs = table.io.get_fs(scheme)
+ else:
+ raise ValueError(f"Expected PyArrowFileIO, got: {table.io}")
+
+ projected_field_ids = projected_schema.field_ids
+
+ tables = []
+ for task in files:
+ _, path = PyArrowFileIO.parse_location(task.file.file_path)
+
+ # Get the schema
+ with fs.open_input_file(path) as fout:
+ parquet_schema = pq.read_schema(fout)
+ schema_raw = parquet_schema.metadata.get(ICEBERG_SCHEMA)
+ file_schema = Schema.parse_raw(schema_raw)
+
+ file_project_schema = prune_columns(file_schema, projected_field_ids)
Review Comment:
Yes, this will prune the fields that we don't need, so we only load the
column that we're going to need, lowering the pressure on the memory. The magic
to match the schema happens in `to_final_schema`, and then we just concat the
tables. Since the table is already in the correct format, we can just concat
them, with the zero-copy concatenation:
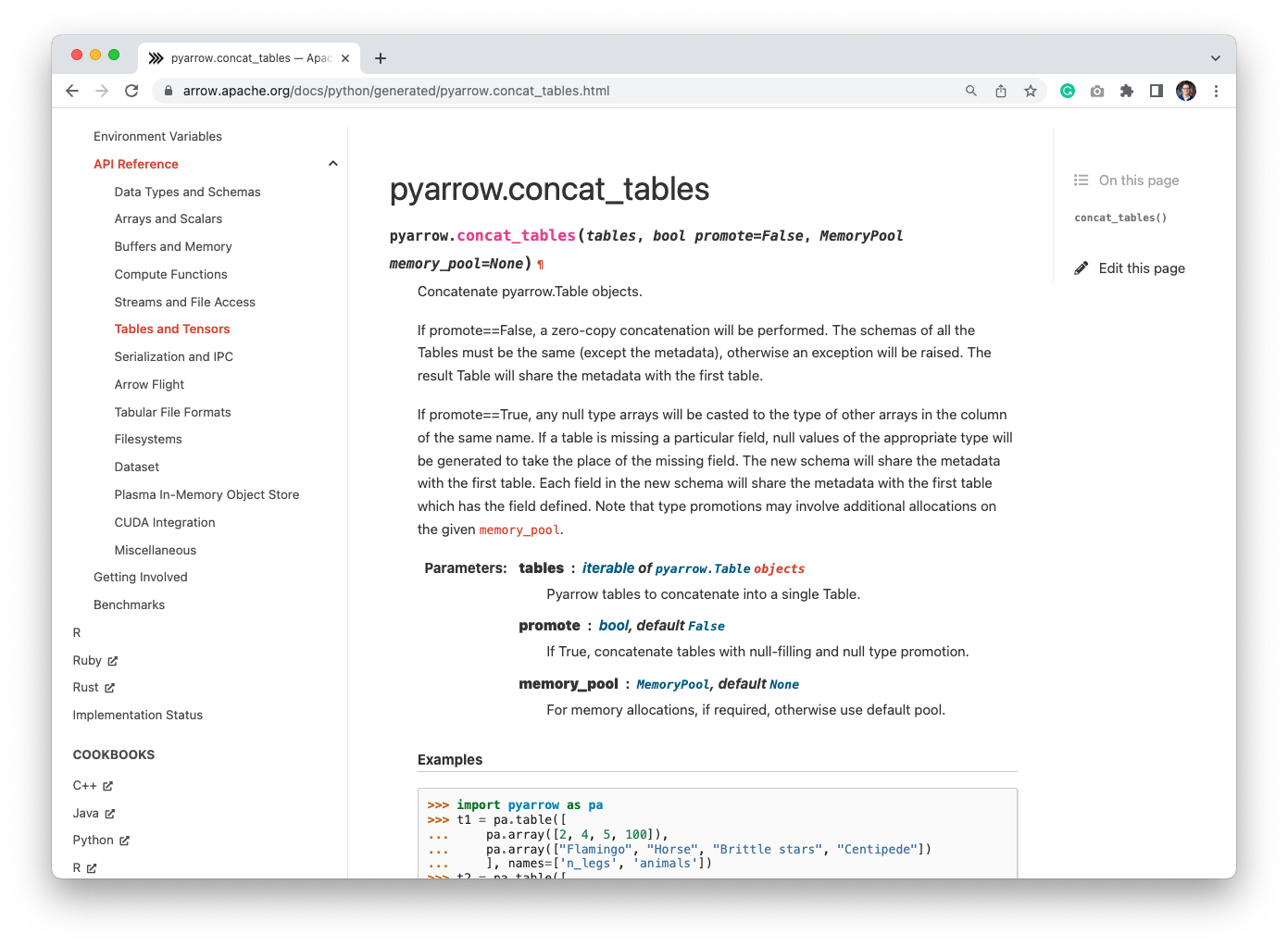
We could also let PyArrow do the null-filling and promotions, but maybe
better to do it ourselves, especially when we start doing things like default
values.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}