> On 七月 15, 2016, 7:23 a.m., Eike Hein wrote: > > Being able to find ??/?? with just wy is cool, but I'm concerned about this > > being a sort of very narrow hack. It's only in a specific KRunner plugin, > > so it won't work in any other thing finding apps by name using lower-level > > APIs. And it only works for Chinese. Littering high-level frontend code > > with language-specific stuff seems wrong. Is there a more central place we > > could put this, and maybe a more extensible way to do it? Like, a framework > > like Ki18n could have a matchInput(haystack, needle) that can do this sort > > of language-specific expansion/transform for haystack to match needle. > > Eike Hein wrote: > Also, more broadly ... why do you need to find Chinese text by pinyin or > pinyin initials in the first place? Why isn't using your IME to convert > pinyin to Chinese good enough? I assume the better IMEs are also smart enough > to suggest ?? for wy anyway? > > Leslie Zhai wrote: > > It's only in a specific KRunner plugin > > Yes, it is better to develop such plugin for KRunner, and I learned how > to write one ;-P https://github.com/xiangzhai/krunner-helloworld > > > And it only works for Chinese > > Yes, the segmentation algroithm is complex > http://nlp.stanford.edu/software/segmenter.shtml and I have no idea how to > Machine Learning without Japanese and Korean dictionaries. > > > Is there a more central place we could put this > > I will pay more attention about ki18n framework. > > > why do you need to find Chinese text by pinyin or pinyin initials > > oh, people might choose English IME by default, so they need to press > Ctrl+Space to switch input method, but directly input Chinese, Japanese or > Korean pinyin is more comvinoent. > > Eike Hein wrote: > > oh, people might choose English IME by default, so they need to press > Ctrl+Space to switch input method, but directly input Chinese, Japanese or > Korean pinyin is more comvinoent > > I'm against littering frontend code with "this Latin text entered might > actually be romanized Chinese, let's check" tests. That just makes no > engineering sense. A framework API used transparently in places where it > makes sense, and extensible to other languages: Maybe. But really the general > place where pinyin to Chinese conversion happens is IME. If you want an > automagic IME, that should maybe implemented at the Qt input handling level > somehow. > > I understand why you want it and why it's nice for a specific user, but > it's not a maintainable approach. Should we add code for every language that > is frequently entered in a romanized from to servicerunner and every other > place, so in the end we copy 1000 lines of code to lots of codebases? > > Leslie Zhai wrote: > Hi Eike, > > As you suggested I will develop a KRunner plugin for KJieba > https://github.com/isoft-linux/kjieba instead of M.O.D plasma ;-) > > For Latin, it is comvinoent to just input letters for querying, but for > Asian Languages (????) there is a convertion, just like what you mentioned, > between letters and characters, and we often use Pinyin (does not need IME) > to input letters. > > Regards, > Leslie Zhai > > Eike Hein wrote: > > For Latin, it is comvinoent to just input letters for querying, but for > Asian Languages (????) there is a convertion, just like what you mentioned, > between letters and characters, and we often use Pinyin (does not need IME) > to input letters. > > Sure pinyin needs an IME :P > > FWIW: I live in Seoul. > > Leslie Zhai wrote: > I live in Beijing, and welcome to Beijing, I can show you around ;-)
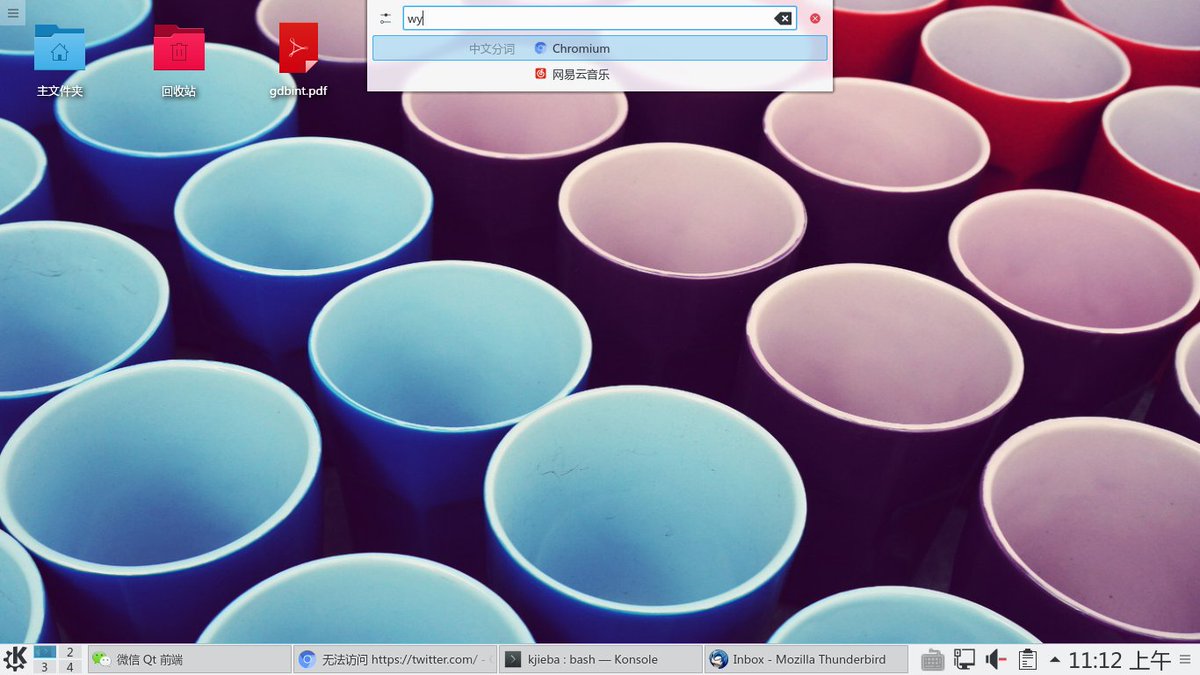
KJieba krunner plugin screenshot shown as https://pbs.twimg.com/media/CoVyg6SUIAEFlln.jpg https://pbs.twimg.com/media/CoVyiSnUIAAeWJE.jpg - Leslie ----------------------------------------------------------- This is an automatically generated e-mail. To reply, visit: https://git.reviewboard.kde.org/r/128454/#review97418 ----------------------------------------------------------- On 七月 16, 2016, 7:19 a.m., Leslie Zhai wrote: > > ----------------------------------------------------------- > This is an automatically generated e-mail. To reply, visit: > https://git.reviewboard.kde.org/r/128454/ > ----------------------------------------------------------- > > (Updated 七月 16, 2016, 7:19 a.m.) > > > Review request for Plasma and Xuetian Weng. > > > Repository: plasma-workspace > > > Description > ------- > > Not like English, each word is seperated by a blank, for example, Hello > World, but in Chinese, ????, it needs to segment Chinese words. > > And Kickoff once supported querying for CJK based on Chinese words > segmentation algroithm, but about last year after KF5, the feature was > dropped, so I added an OPTIONAL requirement for KJieba - libcppjieba Chinese > word segmentation DBus service. > > It is able to input Chinese pinyin or even the first letters to query > Application shown as https://pbs.twimg.com/media/CXSKY6YVAAAvGk8.png > https://pbs.twimg.com/media/CXSKY-UUoAADWEs.png > > > Diffs > ----- > > CMakeLists.txt 74e1518 > runners/services/CMakeLists.txt 7e33a3e > runners/services/servicerunner.h 8d9ad1a > runners/services/servicerunner.cpp aa9d2bd > > Diff: https://git.reviewboard.kde.org/r/128454/diff/ > > > Testing > ------- > > > Thanks, > > Leslie Zhai > >
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_______________________________________________ Plasma-devel mailing list Plasma-devel@kde.org https://mail.kde.org/mailman/listinfo/plasma-devel