ExplorData24 commented on issue #9205: URL: https://github.com/apache/iceberg/issues/9205#issuecomment-1838761423
@nastra Yes, even I tested with iceberg 1.4.2: 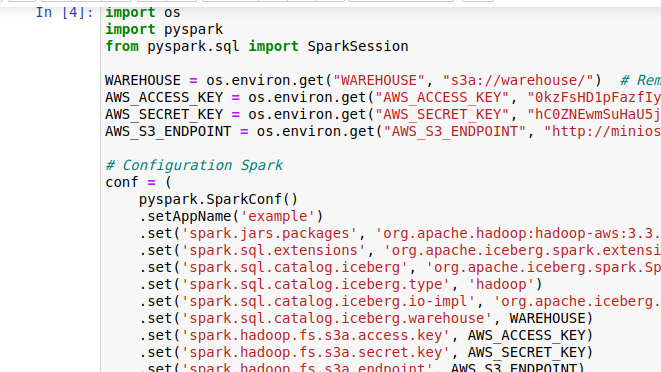  import os import pyspark from pyspark.sql import SparkSession WAREHOUSE = os.environ.get("WAREHOUSE", "s3a://warehouse/") # Remplacez par votre emplacement S3 AWS_ACCESS_KEY = os.environ.get("AWS_ACCESS_KEY", "0kzFsHD1pFazfIyvBi7S") AWS_SECRET_KEY = os.environ.get("AWS_SECRET_KEY", "hC0ZNEwmSuHaU5jjjAv2aMo7oucXcJoj7vfSSH7g") AWS_S3_ENDPOINT = os.environ.get("AWS_S3_ENDPOINT", "http://minioserver:9000";) conf = ( pyspark.SparkConf() .setAppName('example') .set('spark.jars.packages', 'org.apache.hadoop:hadoop-aws:3.3.2,org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.4.2,software.amazon.awssdk:bundle:2.17.178,software.amazon.awssdk:url-connection-client:2.17.178') .set('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .set('spark.sql.catalog.iceberg', 'org.apache.iceberg.spark.SparkCatalog') .set('spark.sql.catalog.iceberg.type', 'hadoop') .set('spark.sql.catalog.iceberg.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .set('spark.sql.catalog.iceberg.warehouse', WAREHOUSE) .set('spark.hadoop.fs.s3a.access.key', AWS_ACCESS_KEY) .set('spark.hadoop.fs.s3a.secret.key', AWS_SECRET_KEY) .set('spark.hadoop.fs.s3a.endpoint', AWS_S3_ENDPOINT) .set('spark.hadoop.fs.s3a.path.style.access', 'true') .set('spark.hadoop.fs.s3a.connection.ssl.enabled', 'true') .set('spark.executor.extraJavaOptions', '-Dcom.amazonaws.services.s3.enableV4=true') .set('spark.driver.extraJavaOptions', '-Dcom.amazonaws.services.s3.enableV4=true') ) spark = SparkSession.builder.config(conf=conf).getOrCreate() print("Spark Running") spark.sql("CREATE TABLE iceberg.tab (name string) USING iceberg;") It always brings together the same error:  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]