On Thu, 23 Jul 2020, Andreas Neumann wrote:
I was reading through
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/
(very interesting article) and I am wondering about how to interpret
read-speed vs compression. With this article I learned about the
relatively new zstd compression and LERC, which is esp. interesting for
LIDAR/DTM data in float32.
In general, when you compress more, the read-speed decreases. So an
uncompressed file would read very fast. But isn't this gain in read
speed at the expense that you have to read a substantially higher amount
of data when you use uncompressed or low-compressed data?
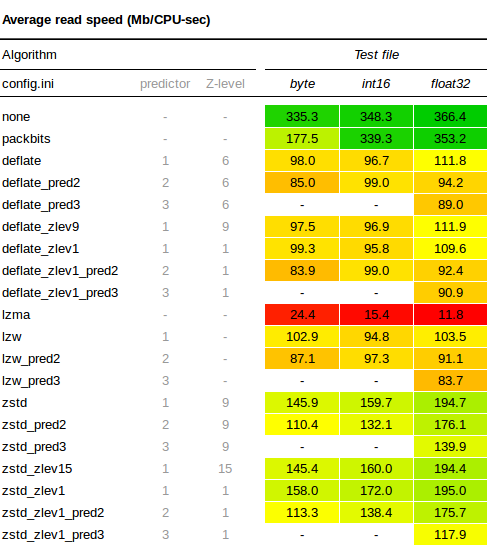
E.g. in the table
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/read_results.png
when you read a float32 dtm with zstd compression, predictor 3 and
zstd_level 9, it shows a substantially lower read rate compared to
predictor 1 (not optimized for float32). But given that predictor 3
compresses substantially better than predictor 1 for float32, isn't the
read-rate "overall" just as good with predictor 3?
Formulating my question different: isn't the read-rate at
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/read_results.png
a bit distorted by the fact that higher-compression means that you also
have to read substantially smaller file sizes? Shouldn't this table with
the read-rate be kind of "normalized" with the file sizes it has to read
for exactly the same data?
Currently, it just lists MB/CPU-sec.
I agree that the amount of compressed data to be read back is important
in this sort of analysis.
The "read" test code (from
https://github.com/kokoalberti/geotiff-benchmark/blob/master/gtiff_benchmark.py
) is
# Run the read tests on the just created file by decompressing
# it again.
print("READ test: Running on file '{}'".format(option+'.tif'))
read_file_output = os.path.join(tmpdir, 'read.tif')
cmd = ['gdal_translate', '-q', option_file, read_file_output,
'-co', 'TILED=NO', '-co', 'COMPRESS=NONE']
try:
task_clock = perf(cmd=cmd, rep=args.repetitions)
speed = (1/task_clock) * base_file_size
print("READ test: Completed {} repetitions. Average time: {:.2f}s Speed:
{:.2f}Mb/s".format(args.repetitions, task_clock, speed))
except Exception as e:
print("READ test: Failed!")
task_clock = ''
speed = ''
finally:
results.append('{};{};{};{};;;;{}'.format('read', filename, option,
task_clock, speed))
The line
speed = (1/task_clock) * base_file_size
says that the size of the original uncompressed file has been used to
calculate the speed. Since the benchmark code, appears
to be timing reading the compressed data from disk(cache), the
decompression and writing the decompressed data to disk(cache),
this is what you want for an overall performance comparison.
However, the comment
# Run the read tests on the just created file
suggests to me that they will be cached at some level and will
probably still be in memory somewhere (eg filesystem cache),
unless the python benchmarking system know how to invalidate these
caches ...
The compression method that gives the best decompression performance
will depend where the compressed data is currently held;
if the file will be decompressed once from internet the compressed
size may be much more important than if there are many partial
decompressions from in memory data.
Back in the 1990s I remember hearing that some decompression
method actually used fewer instrucions than reading the uncompressed
data from disk.
Machine hardware may also make a difference.
Once upon a time the X server on Sun workstations had two
implementations of each primitive, one where memory was faster
than compute and one where compute was faster then memory.
The installer benchmarked each primitive and selected the one
which was faster on the particular machine.
Since then CPU speeds have increased much more than RAM speed,
so there may be a definite winner on current hardware, or it may
mean that the balance point allows more complex decompression algorithms.
--
Andrew C. Aitchison Kendal, UK
and...@aitchison.me.uk
_______________________________________________
gdal-dev mailing list
gdal-dev@lists.osgeo.org
https://lists.osgeo.org/mailman/listinfo/gdal-dev
{kind=link}