Hi,
I was reading through
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/
(very interesting article) and I am wondering about how to interpret
read-speed vs compression. With this article I learned about the
relatively new zstd compression and LERC, which is esp. interesting for
LIDAR/DTM data in float32.
In general, when you compress more, the read-speed decreases. So an
uncompressed file would read very fast. But isn't this gain in read
speed at the expense that you have to read a substantially higher amount
of data when you use uncompressed or low-compressed data?
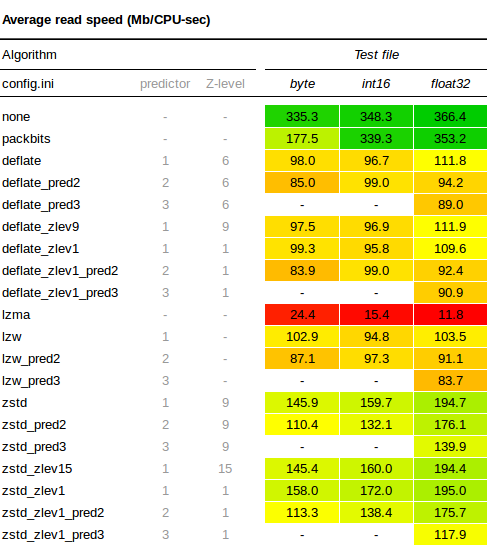
E.g. in the table
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/read_results.png
when you read a float32 dtm with zstd compression, predictor 3 and
zstd_level 9, it shows a substantially lower read rate compared to
predictor 1 (not optimized for float32). But given that predictor 3
compresses substantially better than predictor 1 for float32, isn't the
read-rate "overall" just as good with predictor 3?
Formulating my question different: isn't the read-rate at
https://kokoalberti.com/articles/geotiff-compression-optimization-guide/read_results.png
a bit distorted by the fact that higher-compression means that you also
have to read substantially smaller file sizes? Shouldn't this table with
the read-rate be kind of "normalized" with the file sizes it has to read
for exactly the same data?
Currently, it just lists MB/CPU-sec.
Thanks for the discussion,
Andreas
_______________________________________________
gdal-dev mailing list
gdal-dev@lists.osgeo.org
https://lists.osgeo.org/mailman/listinfo/gdal-dev
{kind=link}