ldwnt opened a new issue, #6956:
URL: https://github.com/apache/iceberg/issues/6956
### Apache Iceberg version
0.13.0
### Query engine
Spark
### Please describe the bug 🐞
The iceberg table being rewritten has ~ 9 million rows and 2GB. The
rewriting spark job runs with parameters: target-file-size-bytes=128M,
spark.driver.memory=20g, spark.executor.memory=3g, num-executors 10,
deploy-mode cluster, master=yarn.
Some executors report failed tasks with the logs as below:
```
23/02/28 05:02:33 WARN [executor-heartbeater] Executor: Issue communicating
with driver in heartbeater
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [10000
milliseconds]. This timeout is controlled by spark.executor.heartbeatInterval
at
org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at
org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at
org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at
scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76)
at org.apache.spark.rpc.RpcEndpointRef.askSync(RpcEndpointRef.scala:103)
at
org.apache.spark.executor.Executor.reportHeartBeat(Executor.scala:1005)
at
org.apache.spark.executor.Executor.$anonfun$heartbeater$1(Executor.scala:212)
at
scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:2019)
at org.apache.spark.Heartbeater$$anon$1.run(Heartbeater.scala:46)
at
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at
java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at
java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after
[10000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:259)
at
scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:263)
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:293)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
... 13 more
```
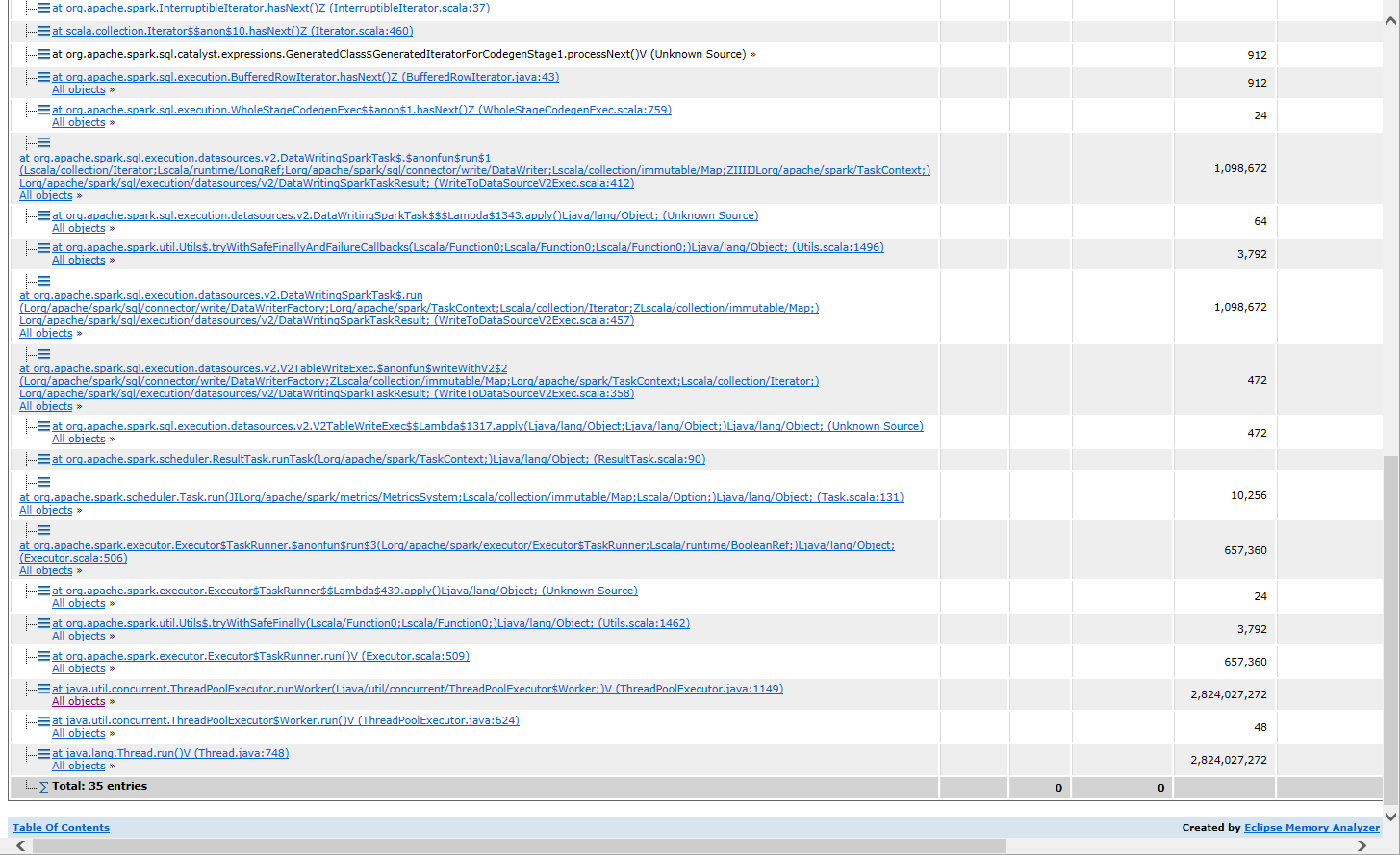
Finally some executors end with oom and the spark job failed. The heap dump
suggests that a huge StructLikeSet is being created from DeleteFilter
```
StructLikeSet deleteSet = Deletes.toEqualitySet(
CloseableIterable.transform(
records, record -> new
InternalRecordWrapper(deleteSchema.asStruct()).wrap(record)),
deleteSchema.asStruct());
```
This table is updated every few days and each time the whole table is
deleted and inserted again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}