Hi,
To reinforce the significance of Fluss -- and to better illustrate how it
differs from existing systems -- I want to share this figure with the community
(courtesy of Jark):
https://alibaba.github.io/fluss-docs/assets/images/img7-06886bca9797751895c82d707cb04b2d.jpg
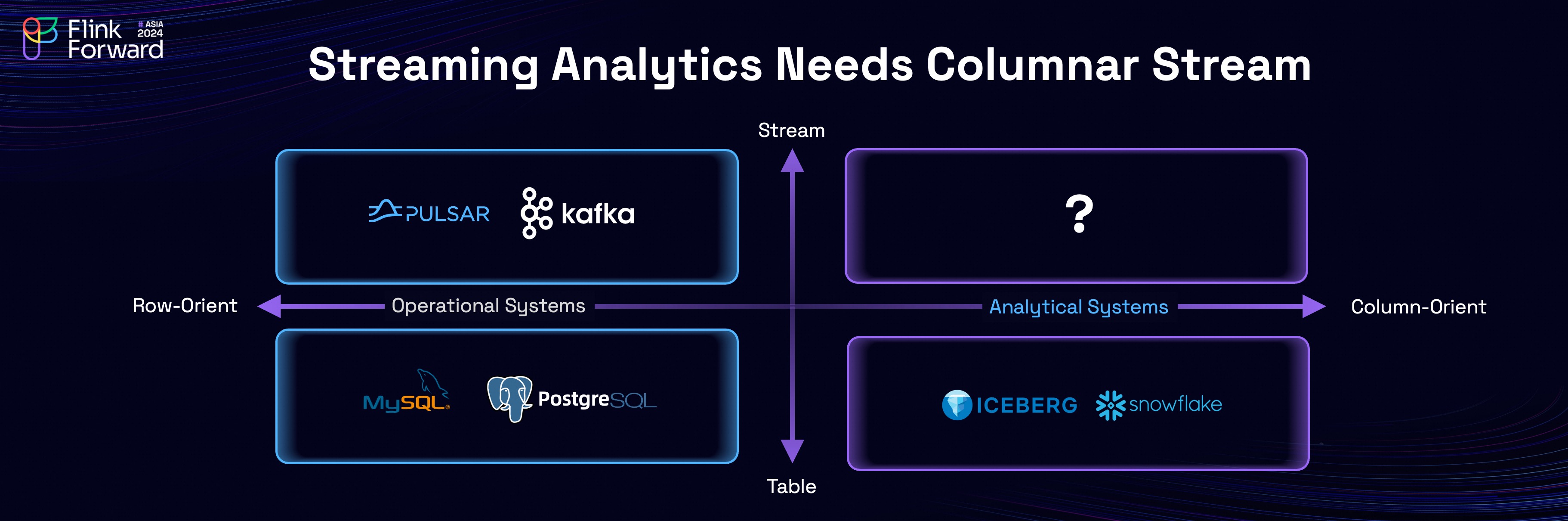
Being a streaming storage with a columnar storage format, Fluss fills the gap
in the upper right quadrant, making it an ideal fit for real-time analytical
use cases.
Since Fluss has been open-sourced, it also has established a very active
community.
Looking forward to the incubation of Fluss.
--
Best,
MKO
GitHub: michaelkoepf
On 2025/05/21 08:43:22 Yu Li wrote:
> Hi All,
>
>
> I would like to propose Fluss [1] as a new apache incubator project, and
> you can find the proposal [2] of Fluss for more details.
>
>
> Fluss is a distributed storage service designed to deliver high
throughput
> and sub-second latency for streaming read and write operations. It
aims to
> provide a unified data layer that bridges real-time processing with data
> lakehouse architectures. Building real-time analytics pipelines on
top of a
> data lakehouse requires key capabilities such as tabular query support,
> efficient data updates, changelog subscriptions, and the ability to
> periodically snapshot data into lake file formats like Apache Iceberg and
> Apache Paimon — functionalities that existing message queue systems
such as
> Apache Kafka are not well suited to address.
>
>
> To tackle these challenges, Fluss offers the following features:
>
>
> 1. *Table-Oriented Data Model, Not Topics.* Unlike traditional messaging
> systems that rely on topics, Fluss treats tables as first-class citizens,
> aligning its data model with that of modern data lakehouses.
>
> 2. *Columnar Stream Storage.* By storing streaming data in a columnar
> format (specifically Apache Arrow), Fluss achieves up to 10x faster read
> performance for analytical queries over streaming data.
>
> 3. *Real-Time Updates and Changelog Subscription.* Fluss natively
supports
> data updates and generates fine-grained changelogs, enabling low-latency
> incremental stream processing and state synchronization.
>
> 4. *Streaming & Lakehouse Unification.* Fluss enhances the stream
> processing capabilities of lakehouse architectures by seamlessly
supporting
> both real-time ingestion and historical analysis within a single system.
>
>
> Fluss is currently deployed in production environments at Alibaba and
many
> other companies, where it has reduced total operational costs by up
to 80%
> compared to traditional message queue systems in a variety of use
cases. In
> addition, the project has gained traction in the open-source community,
> with active adoption from organizations such as ByteDance, AntGroup,
> Ververica, eBay, Dynatrace, and Dream11. Many of these users have also
> contributed code and improvements, helping to form a vibrant and growing
> community with dozens of active developers.
>
>
> The proposed initial committers are eager to join the Apache Software
> Foundation (ASF) to foster broader collaboration and further
strengthen the
> community. We believe that bringing Fluss into the Apache Incubator will
> unlock significant value for the broader open-source ecosystem.
>
>
> I am honored to serve as the champion for this project and will mentor it
> alongside three additional mentors (many thanks to them all):
>
>
> * Becket Qin (j...@apache.org)
>
> * Jingsong Lee (lzljs3620...@apache.org)
>
> * Zili (Tison) Chen (ti...@apache.org)
>
>
> Look forward to your feedback. Thanks.
>
> Best Regards,
> Yu
>
> [1] https://github.com/alibaba/fluss
>
> [2] https://cwiki.apache.org/confluence/display/INCUBATOR/FlussProposal
>
---------------------------------------------------------------------
To unsubscribe, e-mail: general-unsubscr...@incubator.apache.org
For additional commands, e-mail: general-h...@incubator.apache.org
{kind=link}