Thank you for the RFC. It is complete TensorCore support. It is nice that you can support different types and different data layouts, which is not supported in my solution currently.
## Lower Passes vs Intrinsic Intrinsic is a tool for describing what instructions can be done in specific hardware. I believe TensorCore is one kind of specific hardware. It is perfect to use tensor intrinsic. It is standard and easy to maintain (if Nividia add another accelerator, we only need to add another intrinsic rather than a new pass) Another thing is auto tensorization. Just as Tianqi says, our final goal is to generate schedules for all kinds of hardware using tensor intrinsics, which is my major work direction. ## Suggestions and Questions - As we know using TensorCores will decrease precision. So, NVIDIA set up a switch to turn on and off TensorCores in CUBLAS and CUDNN (default not use TensorCores). At least we should let users determine whether use them. - In Volta Arichitecture Whitepaper, TensorCores do production in full precision, rather than half precision. I recommend changing the pattern into `A/B -> Load -> Cast -> Mul -> Add` if we still use pattern matching solution. 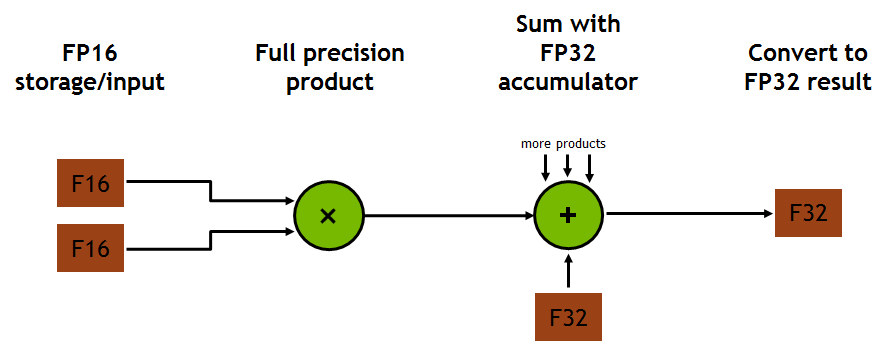 - It shocks me that your solution is even faster than CUBLAS and CUDNN. I try to reproduce the result but fails. Did you use BatchMatMul and BatchConv? And which GPU did you test on? Could you show me the details about the performance? ## Combine with Tensor Intrinsics I am glad to see a different solution for TensorCore. And it seems that it is more complete and faster than mine. However, tensor intrinsic is the solution that Tianqi and I recommend. It would benefit the project and the community if we can cooperate, combining my tensor intrinsic and your complete and well-performance backend. After all, thank you again for this impressive RFC. -- You are receiving this because you are subscribed to this thread. Reply to this email directly or view it on GitHub: https://github.com/dmlc/tvm/issues/4105#issuecomment-541222182
{kind=link}