Actually I always hesitate to package MXNet and its dependencies. On Fri, Jan 17, 2020 at 02:25:46PM +0000, Wookey wrote: > Package: wnpp > Severity: wishlist > Owner: Wookey <woo...@debian.org> > > * Package name : tvm > Version : 0.6.0 > Upstream Author : Apache tvm incubator project > * URL : https://tvm.apache.org/ > * License : Apache 2.0 > Programming Lang: C++, (with go, java, python, rust parts) > Description : Deep Learning compiler There are many deep learning frameworks, where each of them has been backed by a certain business group, e.g.
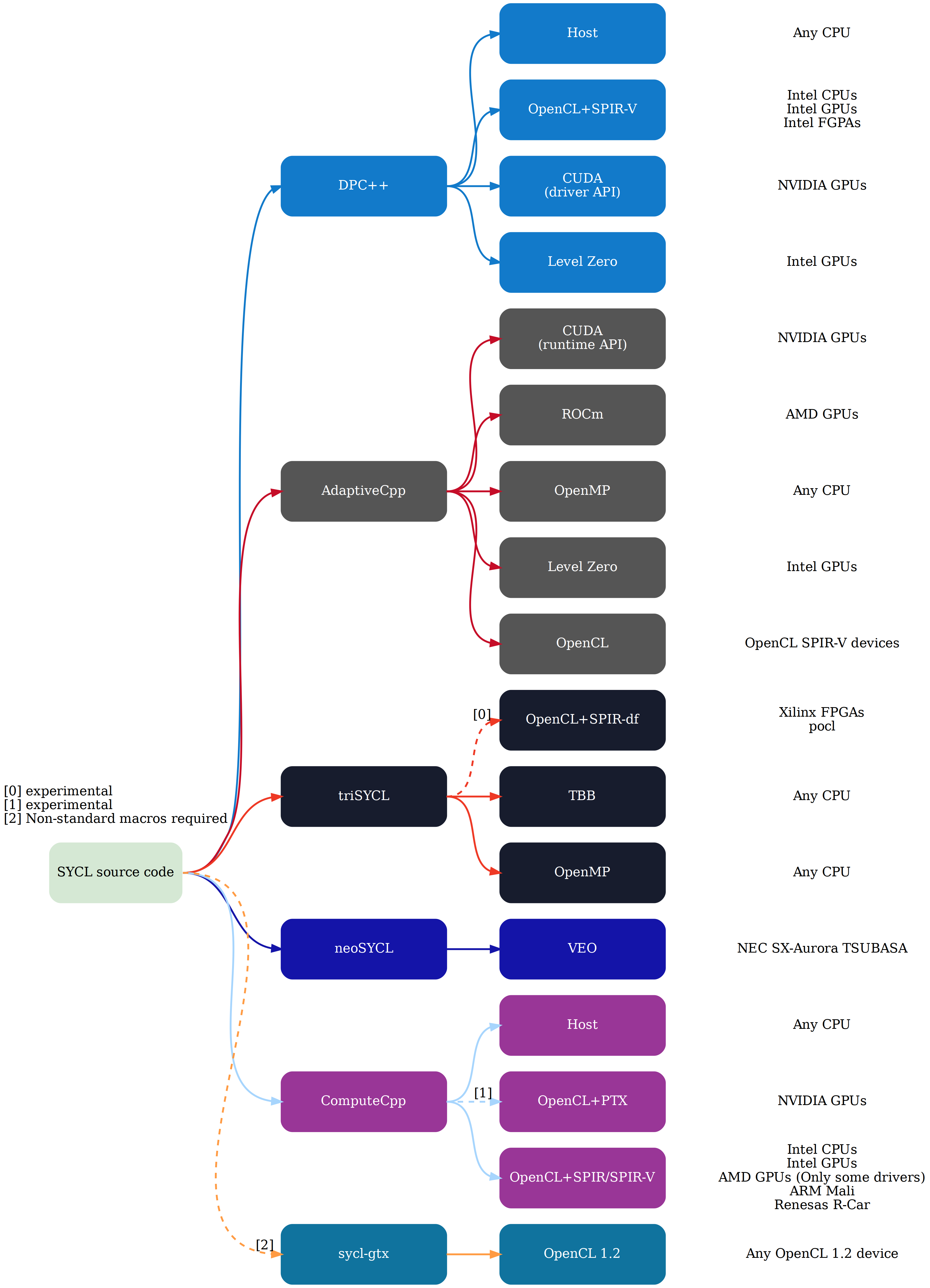
(1) TensorFlow -- Google (2) PyTorch -- Facebook (3) MXNet -- Amazon (4) NLTK -- Micro$oft For general purpose usage (1) and (2) have dominated the market (especially for research, I'm not quite sure what the industry like to use). So a user without dedicated purpose is not likely going to try (3) or (4) or alike. Deep learning frameworks need to be optimized, especially due to the computationally expensive linear algebra operations and other math operations. To this end, some framework may choose to offload the computation to the well-optimized BLAS/LAPACK libraries (e.g. Intel's MKL), offload the computation to dedicated hardware (e.g. GPU via Nvidia CUDA or AMD ROCm), and so on. And, of course, write some compiler. There are a bunch of deep learning compilers out there. Google/TensorFlow has XLA for similar purpose. Intel has ngraph. etc. Such, here comes spontaneously an important question: Is it really necessary to package this deep learning software? In this field things are highly volatile. And as you mentioned the upstream author "Apache incubator". Is it really a good idea to package apache incubator project? https://github.com/apache/incubator-tvm/ If you have specific reason to do so, feel free to go ahead then. IIRC the MXNet/TVM stack is much more distro-friendly than tensorflow and pytorch. > TVM is a deep learning compiler stack for CPUs, GPUs, and specialized > accelerators. It interfaces between the productivity-focused deep > learning frameworks, and the performance- or efficiency-oriented > hardware backends. TVM compiles deep learning models in Keras, MXNet, > PyTorch, Tensorflow, CoreML, and DarkNet into minimum deployable modules > on various hardware backends (CPUs, GPUs and specialised accelerators). > It also provides tools to auto-generate and optimize tensor operators on > more backends with better performance. I didn't look into how TVM works. But if TVM has something to do with SIMD/BLAS/LAPACK/Eigen/CUDA/ROCm and you care about performance, please be careful in these details. > This is part of the growing stack of AI software. Over-grown. Yet-another wheel, maybe. > If anyone else is interested in helping with this package that would > be great because I know very little about AI. I can provide comments and suggestions if you need. There are some WIP work for the mentioned software stack under the deep learning team on salsa https://salsa.debian.org/deeplearning-team > I'm mostly interested > because this piece is the next step up above low-level support like > openCL, arm compute library and armNN (neural network accelerator > support), which I am also working on/helping with. Speaking of OpenCL, you may be interested in SYCL. A higher-level OpenCL. Not only Xilinx[1], but intel[2] also gets interested in SYCL, as SYCL seems to be able to handle many kinds of hardware accelerators such as FPGA, GPU(integrated), GPU(discrete). SYCL might become useful in the future. Getting SYCL into Debian may require cooperation with the LLVM team, the OpenCL team, ROCm team, Nvidia team, and the Arm people, [3] because alternatives mechanism is possibly needed there. [1] https://github.com/triSYCL/triSYCL [2] https://github.com/intel/llvm/tree/sycl [3] https://raw.githubusercontent.com/illuhad/hipSYCL/master/doc/img/sycl-targets.png > I do have access to > people with clue in linaro, where this packaging will be initially > tested, but in the longer term people actually using AI tools in > debian would be best place to look after this. I packaged a commonly used toy/benchmark dataset for sanity testing purpose: https://tracker.debian.org/pkg/dataset-fashion-mnist And you can write an autopkgtest script to do classification on this dataset. (This dataset is fully Expat-licensed.) A machine learning / deep learning framework that fails to reach > ~70% accuracy on the validation dataset is virtually seriously problematic. So, as long as the software keeps doing well on this dataset with our CI infrastructure, it is less likely to go wrong without being noticed.
{kind=link}