This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/master by this push:
new f2b16fc [ZEPPELIN-5458] fix that zeppelin can not parse columns
which contains chinese character
f2b16fc is described below
commit f2b16fc0f26d6d2193d5c8bc9dd5ffb34b45c1eb
Author: zhangxiaoping <zhangxiaop...@shevdc.org>
AuthorDate: Mon Jul 19 11:12:03 2021 +0800
[ZEPPELIN-5458] fix that zeppelin can not parse columns which contains
chinese character
### What is this PR for?
fix that zeppelin can not parse columns which contains chinese character
this PR do two things
the first one thing insert a special character (/u0001) which nerver use
after every chinese character,
so zeppeline can split string correctly, replace /u0001 with empty string,
before add record to rows
the second thing avoid that chinese character is escaped.
### What type of PR is it?
Bug Fix
### Todos
* [ ] - Task
### What is the Jira issue?
https://issues.apache.org/jira/browse/ZEPPELIN-5458
### How should this be tested?
already added test case in test units
### Screenshots (if appropriate)
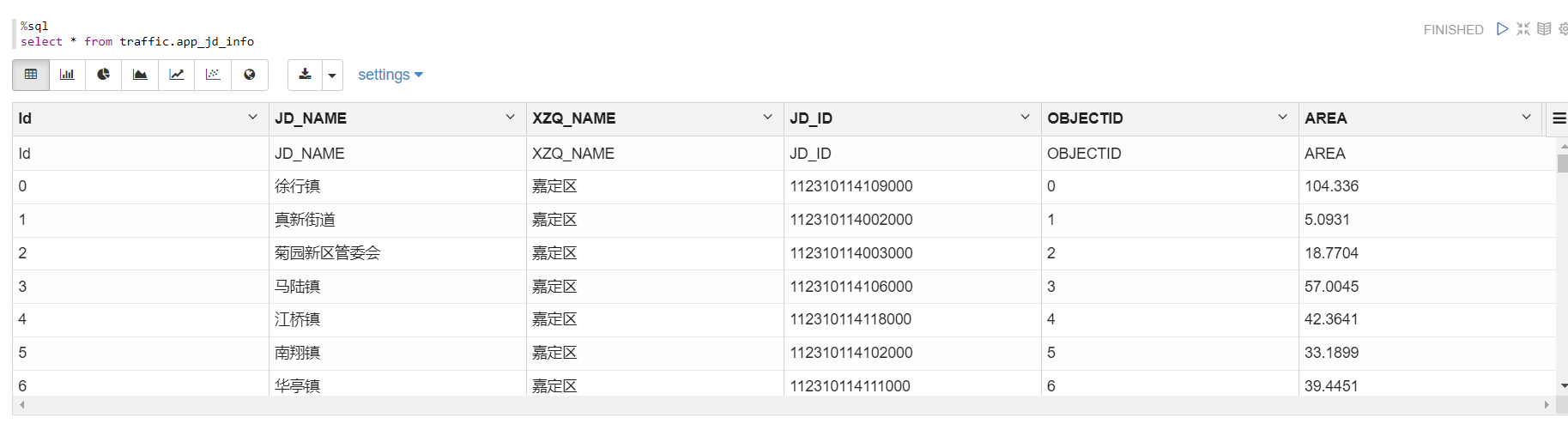
### Questions:
* Does the licenses files need update? no
* Is there breaking changes for older versions? no
* Does this needs documentation? no
Author: zhangxiaoping <zhangxiaop...@shevdc.org>
Closes #4179 from zhxiaoping/bugfix and squashes the following commits:
6af3991624 [zhangxiaoping] Increase the range that char is not escaped and
add comment
383bc026d4 [zhangxiaoping] fix that chinese character display wrong
---
.../zeppelin/livy/LivySparkSQLInterpreter.java | 132 +++++++++++++++++++--
.../zeppelin/livy/LivySQLInterpreterTest.java | 4 +-
2 files changed, 125 insertions(+), 11 deletions(-)
diff --git
a/livy/src/main/java/org/apache/zeppelin/livy/LivySparkSQLInterpreter.java
b/livy/src/main/java/org/apache/zeppelin/livy/LivySparkSQLInterpreter.java
index 4faf9c8..40aa363 100644
--- a/livy/src/main/java/org/apache/zeppelin/livy/LivySparkSQLInterpreter.java
+++ b/livy/src/main/java/org/apache/zeppelin/livy/LivySparkSQLInterpreter.java
@@ -19,9 +19,18 @@ package org.apache.zeppelin.livy;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
-import java.util.Arrays;
+
+import java.io.IOException;
+import java.io.StringWriter;
+import java.io.Writer;
+import java.util.ArrayList;
import java.util.HashMap;
+import java.util.List;
+import java.util.Properties;
+import java.util.Arrays;
import java.util.Map;
+import java.util.Locale;
+
import org.apache.commons.lang3.StringUtils;
import org.apache.zeppelin.interpreter.InterpreterContext;
import org.apache.zeppelin.interpreter.InterpreterException;
@@ -33,11 +42,6 @@ import org.apache.zeppelin.interpreter.ResultMessages;
import org.apache.zeppelin.scheduler.Scheduler;
import org.apache.zeppelin.scheduler.SchedulerFactory;
-import java.util.ArrayList;
-import java.util.List;
-import java.util.Properties;
-
-import static org.apache.commons.lang3.StringEscapeUtils.escapeEcmaScript;
/**
* Livy SparkSQL Interpreter for Zeppelin.
@@ -51,7 +55,6 @@ public class LivySparkSQLInterpreter extends
BaseLivyInterpreter {
"zeppelin.livy.spark.sql.maxResult";
private LivySparkInterpreter sparkInterpreter;
- private String codeType = null;
private boolean isSpark2 = false;
private int maxResult = 1000;
@@ -197,7 +200,22 @@ public class LivySparkSQLInterpreter extends
BaseLivyInterpreter {
return rows;
}
- protected List<String> parseSQLOutput(String output) {
+ protected List<String> parseSQLOutput(String str) {
+ // the regex is referred to org.apache.spark.util.Utils#fullWidthRegex
+ // for spark every chinese character has two placeholder(one placeholder
is one char)
+ // for zeppelin it has only one placeholder.
+ // insert a special character (/u0001) which never use after every chinese
character
+ String fullWidthRegex = "([" +
+ "\u1100-\u115F" +
+ "\u2E80-\uA4CF" +
+ "\uAC00-\uD7A3" +
+ "\uF900-\uFAFF" +
+ "\uFE10-\uFE19" +
+ "\uFE30-\uFE6F" +
+ "\uFF00-\uFF60" +
+ "\uFFE0-\uFFE6" +
+ "])";
+ String output = str.replaceAll(fullWidthRegex, "$1\u0001");
List<String> rows = new ArrayList<>();
// Get first line by breaking on \n. We can guarantee
// that \n marks the end of the first line, but not for
@@ -235,7 +253,12 @@ public class LivySparkSQLInterpreter extends
BaseLivyInterpreter {
List<String> cells = new ArrayList<>();
for (Pair pair : pairs) {
// strip the blank space around the cell and escape the string
- cells.add(escapeEcmaScript(line.substring(pair.start,
pair.end)).trim());
+ // replace /u0001 with empty string just because we insert it before
+ // escapeJavaStyleString is referred to
+ // org.apache.commons.lang3.StringEscapeUtils.escapeEcmaScript
+ // but make a little change that avoid chinese character is escaped
+ cells.add(escapeJavaStyleString(line.substring(pair.start, pair.end)
+ .replaceAll("\u0001", "")).trim());
}
rows.add(StringUtils.join(cells, "\t"));
}
@@ -246,6 +269,97 @@ public class LivySparkSQLInterpreter extends
BaseLivyInterpreter {
return rows;
}
+ private static String escapeJavaStyleString(String str) {
+ if (str == null) {
+ return null;
+ }
+ try {
+ StringWriter writer = new StringWriter(str.length() * 2);
+ escapeJavaStyleString(writer, str);
+ return writer.toString();
+ } catch (IOException ioe) {
+ // this should never ever happen while writing to a StringWriter
+ throw new RuntimeException(ioe);
+ }
+ }
+
+ private static void escapeJavaStyleString(Writer out, String str) throws
IOException {
+ if (out == null) {
+ throw new IllegalArgumentException("The Writer must not be null");
+ }
+ if (str == null) {
+ return;
+ }
+ int sz;
+ sz = str.length();
+ for (int i = 0; i < sz; i++) {
+ char ch = str.charAt(i);
+
+ // handle unicode
+ if (ch > 0xfff) {
+ out.write(ch);
+ } else if (ch > 0xff) {
+ out.write("\\u0" + hex(ch));
+ } else if (ch > 0x7f) {
+ out.write("\\u00" + hex(ch));
+ } else if (ch < 32) {
+ switch (ch) {
+ case '\b' :
+ out.write('\\');
+ out.write('b');
+ break;
+ case '\n' :
+ out.write('\\');
+ out.write('n');
+ break;
+ case '\t' :
+ out.write('\\');
+ out.write('t');
+ break;
+ case '\f' :
+ out.write('\\');
+ out.write('f');
+ break;
+ case '\r' :
+ out.write('\\');
+ out.write('r');
+ break;
+ default :
+ if (ch > 0xf) {
+ out.write("\\u00" + hex(ch));
+ } else {
+ out.write("\\u000" + hex(ch));
+ }
+ break;
+ }
+ } else {
+ switch (ch) {
+ case '\'' :
+ out.write('\\');
+ break;
+ case '"' :
+ out.write('\\');
+ out.write('"');
+ break;
+ case '\\' :
+ out.write('\\');
+ out.write('\\');
+ break;
+ case '/' :
+ out.write('\\');
+ break;
+ default :
+ out.write(ch);
+ break;
+ }
+ }
+ }
+ }
+
+ private static String hex(char ch) {
+ return Integer.toHexString(ch).toUpperCase(Locale.ENGLISH);
+ }
+
/**
* Represent the start and end index of each cell.
*/
diff --git
a/livy/src/test/java/org/apache/zeppelin/livy/LivySQLInterpreterTest.java
b/livy/src/test/java/org/apache/zeppelin/livy/LivySQLInterpreterTest.java
index baa930f..06f475d 100644
--- a/livy/src/test/java/org/apache/zeppelin/livy/LivySQLInterpreterTest.java
+++ b/livy/src/test/java/org/apache/zeppelin/livy/LivySQLInterpreterTest.java
@@ -76,12 +76,12 @@ public class LivySQLInterpreterTest {
rows = sqlInterpreter.parseSQLOutput("+---+---+\n" +
"| a| b|\n" +
"+---+---+\n" +
- "| 1| 1a|\n" +
+ "| 1| 你|\n" +
"| 2| 2b|\n" +
"+---+---+");
assertEquals(3, rows.size());
assertEquals("a\tb", rows.get(0));
- assertEquals("1\t1a", rows.get(1));
+ assertEquals("1\t你", rows.get(1));
assertEquals("2\t2b", rows.get(2));
{kind=link}