This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/master by this push:
new c40b1bc [ZEPPELIN-5325] Broken table column at yarn.html
c40b1bc is described below
commit c40b1bcfb179d034a865397b80ebcdcad5339a84
Author: cuspymd <cusp...@gmail.com>
AuthorDate: Wed Apr 14 16:01:57 2021 +0000
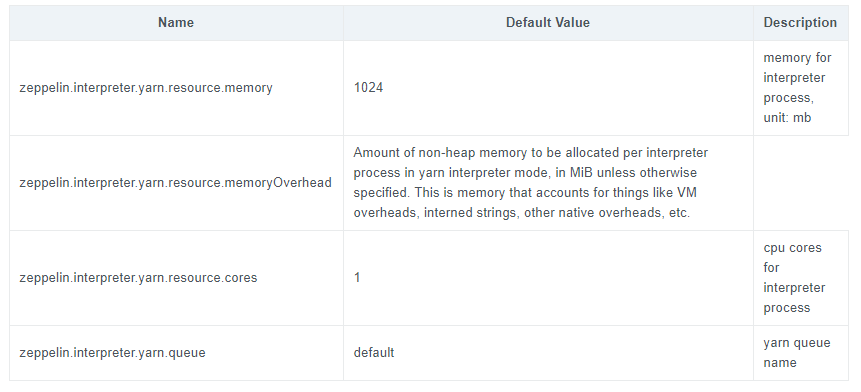
[ZEPPELIN-5325] Broken table column at yarn.html
### What is this PR for?
Add missing column of table in yarn document
### What type of PR is it?
[Documentation]
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-5325
### How should this be tested?
* Check updated document locally
### Screenshots (if appropriate)
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
Author: cuspymd <cusp...@gmail.com>
Closes #4095 from cuspymd/fix-table-yarn and squashes the following commits:
c2876b360 [cuspymd] Add missing column of table in yarn document
---
docs/quickstart/yarn.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/docs/quickstart/yarn.md b/docs/quickstart/yarn.md
index c283a2a..60fb48e 100644
--- a/docs/quickstart/yarn.md
+++ b/docs/quickstart/yarn.md
@@ -51,6 +51,7 @@ Besides that, you can also specify other properties as
following table.
</tr>
<tr>
<td>zeppelin.interpreter.yarn.resource.memoryOverhead</td>
+ <td>384</td>
<td>Amount of non-heap memory to be allocated per interpreter process in
yarn interpreter mode, in MiB unless otherwise specified. This is memory that
accounts for things like VM overheads, interned strings, other native
overheads, etc.</td>
</tr>
<tr>
@@ -72,4 +73,4 @@ There're several differences between yarn interpreter mode
with non-yarn interpr
* New yarn app will be allocated for the interpreter process.
* Any local path setting won't work in yarn interpreter process. E.g. if you
run python interpreter in yarn interpreter mode, then you need to make sure the
python executable of `zeppelin.python` exist in all the nodes of yarn cluster.
Because the python interpreter may launch in any node.
-* Don't use it for spark interpreter. Instead use spark's built-in yarn-client
or yarn-cluster which is more suitable for spark interpreter.
\ No newline at end of file
+* Don't use it for spark interpreter. Instead use spark's built-in yarn-client
or yarn-cluster which is more suitable for spark interpreter.
{kind=link}