This is an automated email from the ASF dual-hosted git repository.
ruihangl pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new e0babea152 [Docs] Clean up architecture docs: remove duplicates, fix
stale content (#19399)
e0babea152 is described below
commit e0babea1528b43d3af42b351fc0173601849e1ec
Author: Shushi Hong <[email protected]>
AuthorDate: Mon Apr 13 10:26:41 2026 -0400
[Docs] Clean up architecture docs: remove duplicates, fix stale content
(#19399)
- Remove duplicate `tvm/s_tir/meta_schedule` and `tvm/s_tir/dlight`
sections from `arch/index.rst` (already covered in the `tvm/s_tir`
section with cross-reference to TensorIR Deep Dive)
- Remove duplicate `device_target_interactions` toctree entry (was
listed under both `tvm/runtime` and `tvm/target`; keep only under
`tvm/target`)
- Remove duplicate CUDA pipeline listing in `arch/fusion.rst` "How
Backends Use Fusion" section (already shown in Overview); add
cross-reference to BYOC doc
- Remove duplicated intro sentences in `arch/relax_vm.rst` that were
identical to `arch/index.rst`
- Fix `R.call_dps` → `R.call_dps_packed` (the former does not exist)
- Replace outdated GraphExecutor example
(`set_input`/`run`/`get_output`) with Relax VM example (GraphExecutor
has been removed from the codebase)
- Replace broken external `mlc.ai` image link (returns 404) with local
image in `deep_dive/relax/learning.rst`
- Fix stale `use pass instrument` link in `arch/pass_infra.rst` that
pointed to an unrelated page
---
docs/_static/img/e2e_fashionmnist_mlp_model.png | Bin 0 -> 106160 bytes
docs/arch/fusion.rst | 7 ++--
docs/arch/index.rst | 41 +++++++-----------------
docs/arch/pass_infra.rst | 3 +-
docs/arch/relax_vm.rst | 8 ++---
docs/deep_dive/relax/learning.rst | 2 +-
6 files changed, 18 insertions(+), 43 deletions(-)
diff --git a/docs/_static/img/e2e_fashionmnist_mlp_model.png
b/docs/_static/img/e2e_fashionmnist_mlp_model.png
new file mode 100644
index 0000000000..7ee156e66f
Binary files /dev/null and b/docs/_static/img/e2e_fashionmnist_mlp_model.png
differ
diff --git a/docs/arch/fusion.rst b/docs/arch/fusion.rst
index 5b7e755f94..5f4a575c08 100644
--- a/docs/arch/fusion.rst
+++ b/docs/arch/fusion.rst
@@ -345,10 +345,7 @@ How Backends Use Fusion
-----------------------
The default backend pipelines (CUDA, ROCm, CPU, etc.) all include ``FuseOps``
+ ``FuseTIR``
-in their ``legalize_passes`` phase for automatic fusion. For example, the CUDA
pipeline
-(``python/tvm/relax/backend/cuda/pipeline.py``) runs::
-
- LegalizeOps → AnnotateTIROpPattern → FoldConstant → FuseOps → FuseTIR →
DLight
+in their ``legalize_passes`` phase for automatic fusion, as shown in the
`Overview`_ above.
For external library dispatch (cuBLAS, CUTLASS, cuDNN, DNNL),
``FuseOpsByPattern`` is used
separately. These are **not** included in the default pipeline — users add
them explicitly
@@ -358,7 +355,7 @@ when building a custom compilation flow. The typical
sequence is:
offloaded to external libraries. For example, CUTLASS patterns match
matmul+bias+activation combinations
(``python/tvm/relax/backend/cuda/cutlass.py``).
Functions marked by patterns are annotated with ``Composite`` and
optionally ``Codegen``
- attributes.
+ attributes. See :ref:`external-library-dispatch` for the full BYOC pipeline.
2. **Automatic fusion** (``FuseOps`` + ``FuseTIR``): remaining operators that
were not
matched by backend patterns are fused automatically based on their pattern
kinds.
diff --git a/docs/arch/index.rst b/docs/arch/index.rst
index 9479d22948..8dea6c8eaa 100644
--- a/docs/arch/index.rst
+++ b/docs/arch/index.rst
@@ -68,7 +68,7 @@ contains a collection of functions. Currently, we support two
primary variants o
threading, and vector/tensor instructions. It is usually used to represent
an operator program that executes a (possibly-fused) layer in a model.
During the compilation and transformation, all relax operators are lowered to
``tirx::PrimFunc`` or ``TVM PackedFunc``, which can be executed directly
-on the target device, while the calls to relax operators are lowered to calls
to low-level functions (e.g. ``R.call_tir`` or ``R.call_dps``).
+on the target device, while the calls to relax operators are lowered to calls
to low-level functions (e.g. ``R.call_tir`` or ``R.call_dps_packed``).
Transformations
~~~~~~~~~~~~~~~
@@ -160,22 +160,19 @@ following types: POD types(int, float), string,
runtime.PackedFunc, runtime.Modu
:py:class:`tvm.runtime.Module` and :py:class:`tvm.runtime.PackedFunc` are
powerful mechanisms to modularize the runtime. For example, to get the above
`addone` function on CUDA, we can use LLVM to generate the host-side code to
compute the launching parameters(e.g. size of the thread groups) and then call
into another PackedFunc from a CUDAModule that is backed by the CUDA driver
API. The same mechanism can be used for OpenCL kernels.
-The above example only deals with a simple `addone` function. The code snippet
below gives an example of an end-to-end model execution using the same
interface:
+The above example only deals with a simple `addone` function. The code snippet
below gives an example of an end-to-end model execution using the Relax Virtual
Machine, which is built on the same runtime.Module and runtime.PackedFunc
interface:
.. code-block:: python
import tvm
- # Example runtime execution program in python, with types annotated
- factory: tvm.runtime.Module = tvm.runtime.load_module("resnet18.so")
- # Create a stateful graph execution module for resnet18 on cuda(0)
- gmod: tvm.runtime.Module = factory["resnet18"](tvm.cuda(0))
+ from tvm import relax
+ # Load the compiled artifact
+ mod: tvm.runtime.Module = tvm.runtime.load_module("resnet18.so")
+ # Create a VM instance on cuda(0)
+ vm = relax.VirtualMachine(mod, tvm.cuda(0))
data: tvm.runtime.Tensor = get_input_data()
- # set input
- gmod["set_input"](0, data)
- # execute the model
- gmod["run"]()
- # get the output
- result = gmod["get_output"](0).numpy()
+ # Run the model — vm["main"] returns a PackedFunc
+ result = vm["main"](data).numpy()
The main take away is that runtime.Module and runtime.PackedFunc are
sufficient to encapsulate both operator level programs (such as addone), as
well as the end-to-end models.
@@ -236,10 +233,9 @@ for learning-based optimizations.
:maxdepth: 1
introduction_to_module_serialization
- device_target_interactions
Relax Virtual Machine
-^^^^^^^^^^^^^^^^^^^^^
+~~~~~~~~~~~~~~~~~~~~~
Relax defines *what* to compute — it is a graph-level IR that describes the
operators and dataflow
of a model. The Relax Virtual Machine (VM) handles *how* to run it — it is the
runtime component
@@ -257,7 +253,7 @@ pipeline, instruction set details, execution model, and
Python interface.
relax_vm
Disco: Distributed Runtime
-^^^^^^^^^^^^^^^^^^^^^^^^^^
+~~~~~~~~~~~~~~~~~~~~~~~~~~
Disco is TVM's distributed runtime for executing models across multiple
devices. When a model is
too large to fit on a single GPU, the ``relax.distributed`` module annotates
how tensors should be
@@ -416,18 +412,3 @@ and then integrate it into the IRModule.
While possible to construct operators directly via TensorIR or tensor
expressions (TE) for each use case, it is tedious to do so.
`topi` (Tensor operator inventory) provides a set of pre-defined operators
defined by numpy and found in common deep learning workloads.
-tvm/s_tir/meta_schedule
------------------------
-
-MetaSchedule is a system for automated search-based program optimization,
-and can be used to optimize TensorIR schedules. Note that MetaSchedule only
works with static-shape workloads.
-
-tvm/s_tir/dlight
-----------------
-
-DLight is a set of pre-defined, easy-to-use, and performant s_tir schedules.
DLight aims:
-
-- Fully support **dynamic shape workloads**.
-- **Light weight**. DLight schedules provides tuning-free schedule with
reasonable performance.
-- **Robust**. DLight schedules are designed to be robust and general-purpose
for a single rule. And if the rule is not applicable,
- DLight not raise any error and switch to the next rule automatically.
diff --git a/docs/arch/pass_infra.rst b/docs/arch/pass_infra.rst
index aa882f328e..b04868e2c6 100644
--- a/docs/arch/pass_infra.rst
+++ b/docs/arch/pass_infra.rst
@@ -617,7 +617,7 @@ Note that it is recommended to use the ``pass_instrument``
decorator to implemen
``PassInstrument`` instances can be registered through ``instruments``
argument in
:py:class:`tvm.transform.PassContext`.
-`use pass instrument`_ tutorial provides examples for how to implement
``PassInstrument`` with Python APIs.
+See `python/tvm/ir/instrument.py`_ for examples of how to implement
``PassInstrument`` with Python APIs.
.. _pass_instrument_overriden:
@@ -668,4 +668,3 @@ new ``PassInstrument`` are called.
.. _use pass infra:
https://github.com/apache/tvm/blob/main/docs/how_to/tutorials/customize_opt.py
-.. _use pass instrument:
https://github.com/apache/tvm/blob/main/docs/how_to/dev/index.rst
diff --git a/docs/arch/relax_vm.rst b/docs/arch/relax_vm.rst
index dddee57b36..30ce5bd058 100644
--- a/docs/arch/relax_vm.rst
+++ b/docs/arch/relax_vm.rst
@@ -20,11 +20,9 @@
Relax Virtual Machine
=====================
-Relax defines *what* to compute — it is a graph-level IR that describes the
operators and dataflow
-of a model. The Relax Virtual Machine (VM) handles *how* to run it — it is the
runtime component
-that executes the compiled result. This document explains the VM architecture
in detail, covering
-the compilation pipeline from Relax IR to bytecode, the instruction set, the
execution model, and
-the Python-level user interface.
+This document explains the Relax VM architecture in detail, covering the
compilation pipeline
+from Relax IR to bytecode, the instruction set, the execution model, and the
Python-level user
+interface.
Overview
--------
diff --git a/docs/deep_dive/relax/learning.rst
b/docs/deep_dive/relax/learning.rst
index 5590d62e2c..59b97daaa0 100644
--- a/docs/deep_dive/relax/learning.rst
+++ b/docs/deep_dive/relax/learning.rst
@@ -32,7 +32,7 @@ In this chapter, we will use the following model as an
example. This is
a two-layer neural network that consists of two linear operations with
relu activation.
-.. image:: https://mlc.ai/_images/e2e_fashionmnist_mlp_model.png
+.. image:: /_static/img/e2e_fashionmnist_mlp_model.png
:width: 85%
:align: center
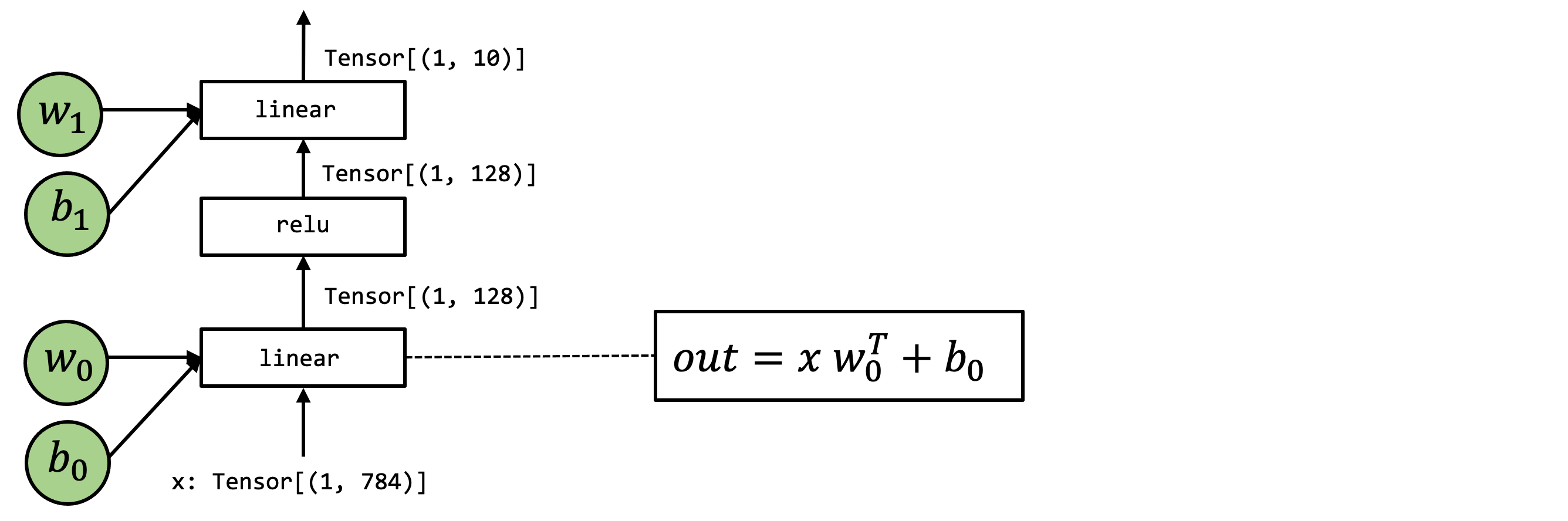{kind=link}