This is an automated email from the ASF dual-hosted git repository.
yaooqinn pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6e4d9d7147af [SPARK-56811][UI] Restore sub-execution grouping on the
SQL tab listing
6e4d9d7147af is described below
commit 6e4d9d7147afdc8d160a72ada9d57edbb86ec138
Author: Kent Yao <[email protected]>
AuthorDate: Wed May 13 21:17:48 2026 +0800
[SPARK-56811][UI] Restore sub-execution grouping on the SQL tab listing
### What changes were proposed in this pull request?
This PR restores sub-execution grouping on the SQL tab listing that was
silently dropped when the listing was switched to server-side pagination in
SPARK-56140.
- Backend (`SqlResource.sqlTable`): accept a new `groupSubExecution` query
parameter (default = cluster config `spark.ui.groupSQLSubExecutionEnabled`).
When enabled, paginate over root executions only and embed each root's children
as `subExecutions: [...]` on the row. Sub-executions whose root is missing from
the filtered set surface as roots so they are never hidden. Fix `recordsTotal`
/ `recordsFiltered` to count root rows in grouped mode so the DataTables
"Showing X to Y of Z entr [...]
- Frontend (`allexecutionspage.js`): read the existing
`group-sub-exec-config` data attribute, forward `groupSubExecution=true|false`
to the server, and append a trailing **Sub Executions** column showing a `+N
sub` toggle on roots that have children. Toggling expands the row using
DataTables `row().child()` with a nested table — matches the SPARK-41752 /
Spark 4.1 layout.
- CSS (`webui-dataTables.css`): minimal styling for the toggle link and the
nested child table (indent + tertiary background).
### Why are the changes needed?
SPARK-41752 introduced sub-execution grouping in Spark 4.1, and SPARK-55875
carried it over when the listing moved to client-side DataTables. SPARK-56140
then switched the listing to server-side pagination but didn't carry over the
grouping logic — every sub-execution now shows up as its own flat row,
regressing the UX for queries such as `CACHE TABLE` and nested CTAS.
### Does this PR introduce _any_ user-facing change?
Yes — the SQL tab listing again folds sub-executions under their root, with
a `+N sub` toggle to expand. Default behaviour is controlled by the existing
`spark.ui.groupSQLSubExecutionEnabled` config (default `true`).
The screenshots below were taken from the same workload (`SELECT`, `CACHE
TABLE`, broadcast join, `DROP TABLE`, `CREATE TABLE … AS`) — `CACHE TABLE` and
the inner `CREATE TABLE` each spawn a sub-execution.
**Before — flat listing (today, post-SPARK-56140):** sub-executions appear
as flat sibling rows; e.g. id 2/3/4 are all `CACHE TABLE people_eng_cached` and
id 7/8/9 are all `nested CTAS`.
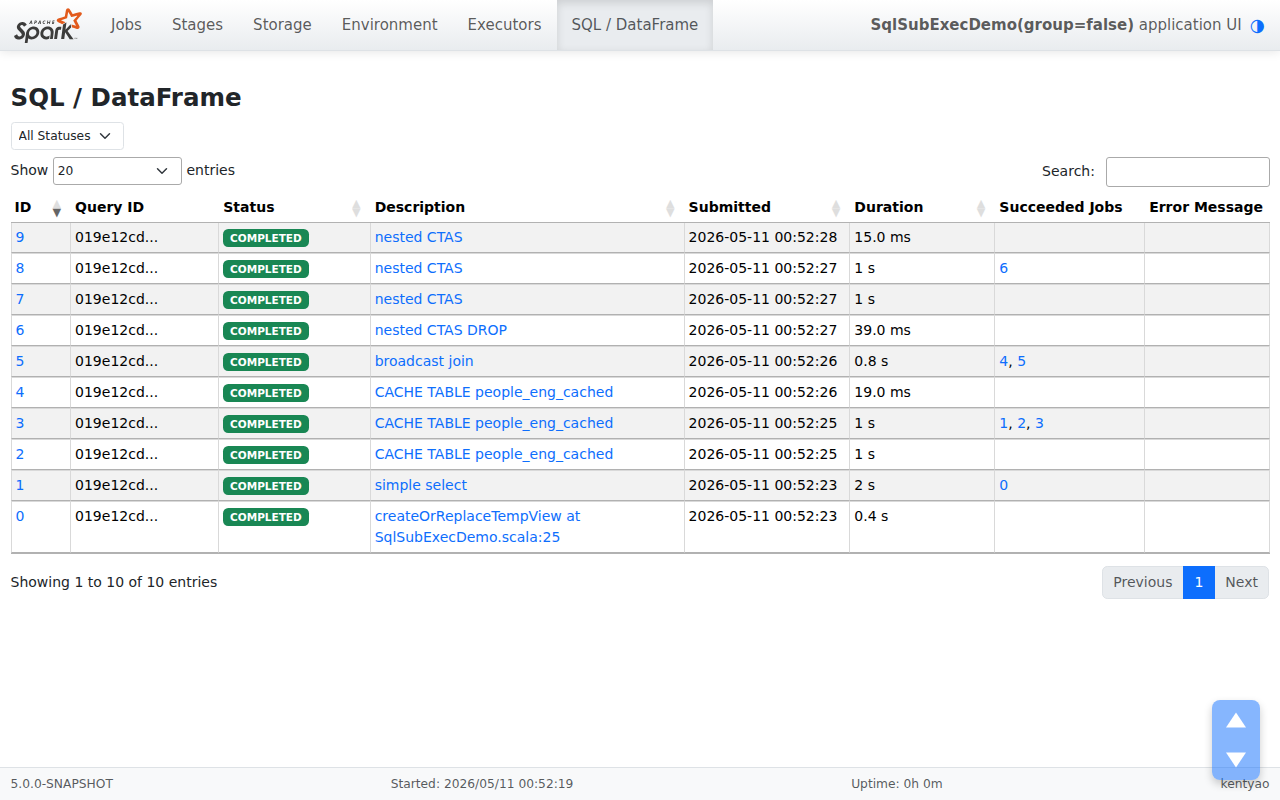
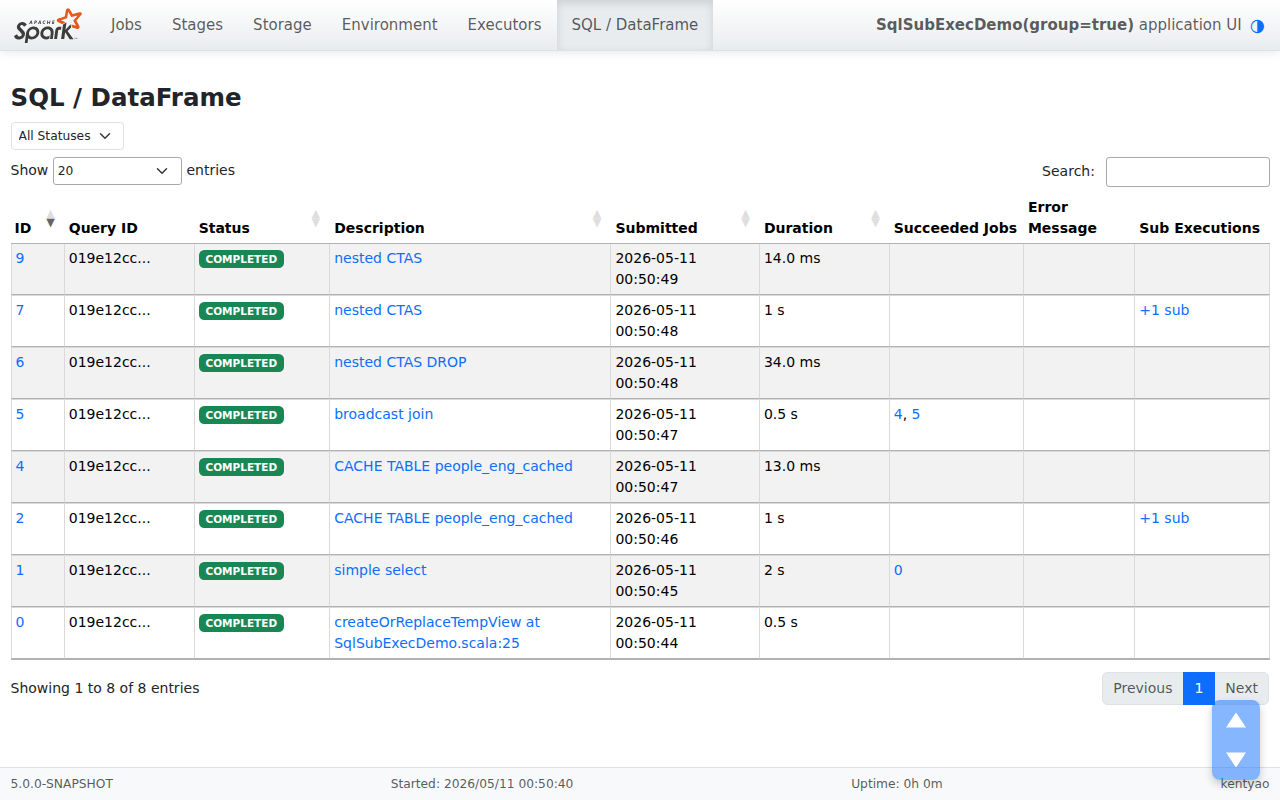
**After — grouped, collapsed:** only roots are listed, with a trailing `+1
sub` toggle on rows that own a sub-execution.
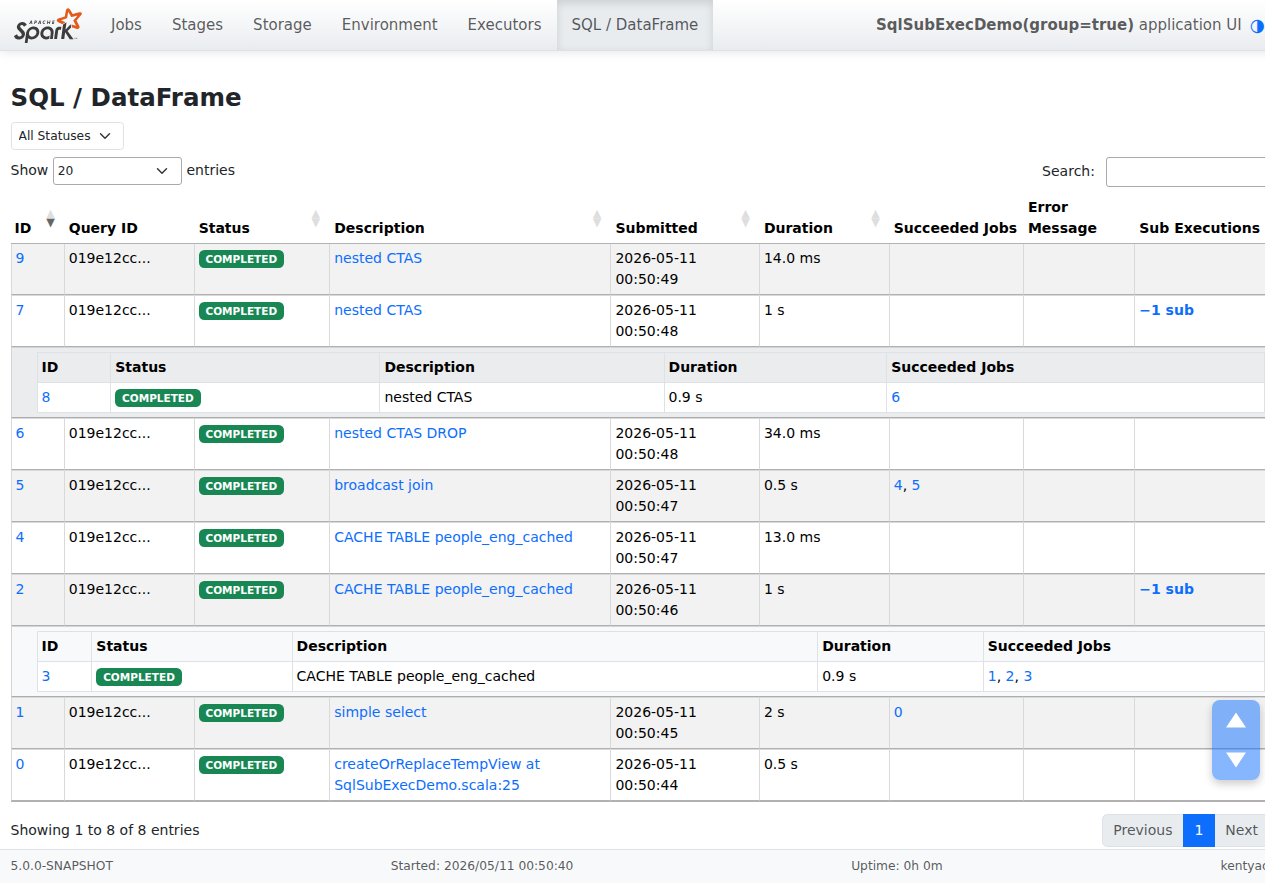
**After — grouped, expanded:** clicking `+1 sub` expands a nested table
inline.
### How was this patch tested?
- New unit test in `SqlResourceWithActualMetricsSuite` covering both
grouped and flat modes against a session that runs `CACHE TABLE` (which
produces a root + sub-execution pair).
- Existing `SqlResourceWithActualMetricsSuite` and
`AllExecutionsPageWithInMemoryStoreSuite` continue to pass.
- Manual verification in a local Spark UI (screenshots above): ran the same
workload twice — once with `spark.ui.groupSQLSubExecutionEnabled=false` (flat)
and once with the default `true` (grouped) — and confirmed both modes render
correctly.
### Was this patch authored or co-authored using generative AI tooling?
Generated-by: GitHub Copilot CLI 1.0.44-2 with Claude Opus 4.7 (Extra high
reasoning)
Closes #55787 from yaooqinn/SPARK-56811.
Authored-by: Kent Yao <[email protected]>
Signed-off-by: Kent Yao <[email protected]>
---
.../apache/spark/ui/static/webui-dataTables.css | 32 +++
.../sql/execution/ui/static/allexecutionspage.js | 229 +++++++++++++++------
.../spark/status/api/v1/sql/SqlResource.scala | 96 +++++++--
.../v1/sql/SqlResourceWithActualMetricsSuite.scala | 114 ++++++++++
4 files changed, 384 insertions(+), 87 deletions(-)
diff --git
a/core/src/main/resources/org/apache/spark/ui/static/webui-dataTables.css
b/core/src/main/resources/org/apache/spark/ui/static/webui-dataTables.css
index 202579c6b67c..e7a8f3ab0839 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/webui-dataTables.css
+++ b/core/src/main/resources/org/apache/spark/ui/static/webui-dataTables.css
@@ -58,4 +58,36 @@ table.dataTable thead .sorting_desc_disabled::after {
div.dataTables_wrapper div.dataTables_length select {
width: 100%;
+}
+
+/* SQL tab sub-execution disclosure (SPARK-56811) */
+table#sql-table td.sub-exec-toggle {
+ white-space: nowrap;
+}
+
+table#sql-table td.sub-exec-toggle a.toggle-sub-exec {
+ text-decoration: none;
+}
+
+table#sql-table td.sub-exec-toggle a.toggle-sub-exec:hover {
+ text-decoration: underline;
+}
+
+table#sql-table tr.shown td.sub-exec-toggle a.toggle-sub-exec {
+ font-weight: 600;
+}
+
+table#sql-table tr.shown + tr > td {
+ background-color: var(--bs-tertiary-bg, #f4f7fa);
+}
+
+table.sub-exec-table {
+ margin-left: 1.5rem !important;
+ width: calc(100% - 1.5rem) !important;
+ background-color: transparent;
+}
+
+table.sub-exec-table thead th {
+ font-weight: 600;
+ background-color: transparent;
}
\ No newline at end of file
diff --git
a/sql/core/src/main/resources/org/apache/spark/sql/execution/ui/static/allexecutionspage.js
b/sql/core/src/main/resources/org/apache/spark/sql/execution/ui/static/allexecutionspage.js
index 34e3be4913ce..b741a18789d6 100644
---
a/sql/core/src/main/resources/org/apache/spark/sql/execution/ui/static/allexecutionspage.js
+++
b/sql/core/src/main/resources/org/apache/spark/sql/execution/ui/static/allexecutionspage.js
@@ -116,6 +116,13 @@ $(document).ready(function () {
}
}
+ // Read the cluster-level grouping toggle rendered into the page by Scala
+ var groupSubExecEnabled = true;
+ var configEl = document.getElementById("group-sub-exec-config");
+ if (configEl) {
+ groupSubExecEnabled = configEl.getAttribute("data-value") === "true";
+ }
+
function init(resolvedAppId) {
var sqlTableEndPoint = createSQLTableEndPoint(resolvedAppId);
@@ -131,6 +138,94 @@ $(document).ready(function () {
'<table id="sql-table" class="table table-striped compact cell-border" '
+
'style="width:100%"></table>';
+ var columns = [
+ {
+ data: "id", name: "id", title: "ID",
+ render: function (data, type) {
+ if (type !== "display") return data;
+ var basePath = uiRoot + appBasePath;
+ return '<a href="' + basePath + '/SQL/execution/?id=' + data + '">' +
+ data + '</a>';
+ }
+ },
+ {
+ data: "queryId", name: "queryId", title: "Query ID",
+ orderable: false,
+ render: function (data, type) {
+ if (type !== "display" || !data) return data || "";
+ var safe = escapeHtml(data);
+ return '<span title="' + safe + '">' + escapeHtml(data.substring(0,
8)) + '...</span>';
+ }
+ },
+ {
+ data: "status", name: "status", title: "Status",
+ render: function (data, type) {
+ if (type !== "display") return data;
+ return statusBadge(data);
+ }
+ },
+ {
+ data: "description", name: "description", title: "Description",
+ render: function (data, type, row) {
+ if (type !== "display") return data || "";
+ return descriptionHtml({ id: row.id, description: data });
+ }
+ },
+ {
+ data: "submissionTime", name: "submissionTime", title: "Submitted",
+ render: function (data, type) {
+ if (type !== "display") return data;
+ return formatDateSql(data);
+ }
+ },
+ {
+ data: "duration", name: "duration", title: "Duration",
+ render: function (data, type) {
+ if (type !== "display") return data;
+ return formatDurationSql(data);
+ }
+ },
+ {
+ data: "jobIds", name: "jobIds", title: "Succeeded Jobs",
+ orderable: false,
+ render: function (data, type) {
+ if (type !== "display") return (data || []).join(",");
+ return jobIdLinks(data || []);
+ }
+ },
+ {
+ data: "errorMessage", name: "errorMessage", title: "Error Message",
+ orderable: false,
+ render: function (data, type) {
+ if (type !== "display" || !data) return data || "";
+ if (data.length > 100) {
+ return '<span title="' + escapeHtml(data) + '">' +
+ escapeHtml(data.substring(0, 100)) + '...</span>';
+ }
+ return escapeHtml(data);
+ }
+ }
+ ];
+ if (groupSubExecEnabled) {
+ // Trailing "Sub Executions" column matching the SPARK-41752 / 4.1
layout:
+ // shows "+N sub" when the root has children, blank otherwise. Click to
+ // expand a child row containing the sub-execution rows.
+ columns.push({
+ data: null, name: "subExecutions", title: "Sub Executions",
+ orderable: false, searchable: false,
+ className: "sub-exec-toggle",
+ render: function (data, type, row) {
+ if (type !== "display") return "";
+ var subs = row.subExecutions || [];
+ if (subs.length === 0) return "";
+ var childId = "sub-exec-" + row.id;
+ return '<a href="#" class="toggle-sub-exec" role="button" ' +
+ 'aria-expanded="false" aria-controls="' + childId + '">' +
+ '+' + subs.length + ' sub</a>';
+ }
+ });
+ }
+
var table = $("#sql-table").DataTable({
serverSide: true,
processing: true,
@@ -146,83 +241,83 @@ $(document).ready(function () {
if (sel) {
d.status = sel;
}
+ d.groupSubExecution = groupSubExecEnabled ? "true" : "false";
},
dataSrc: function (json) { return json.aaData; },
error: function () {
$("#sql-table_processing").css("display", "none");
}
},
- columns: [
- {
- data: "id", name: "id", title: "ID",
- render: function (data, type) {
- if (type !== "display") return data;
- var basePath = uiRoot + appBasePath;
- return '<a href="' + basePath + '/SQL/execution/?id=' + data +
'">' +
- data + '</a>';
- }
- },
- {
- data: "queryId", name: "queryId", title: "Query ID",
- orderable: false,
- render: function (data, type) {
- if (type !== "display" || !data) return data || "";
- return '<span title="' + data + '">' + data.substring(0, 8) +
'...</span>';
- }
- },
- {
- data: "status", name: "status", title: "Status",
- render: function (data, type) {
- if (type !== "display") return data;
- return statusBadge(data);
- }
- },
- {
- data: "description", name: "description", title: "Description",
- render: function (data, type, row) {
- if (type !== "display") return data || "";
- return descriptionHtml({ id: row.id, description: data });
- }
- },
- {
- data: "submissionTime", name: "submissionTime", title: "Submitted",
- render: function (data, type) {
- if (type !== "display") return data;
- return formatDateSql(data);
- }
- },
- {
- data: "duration", name: "duration", title: "Duration",
- render: function (data, type) {
- if (type !== "display") return data;
- return formatDurationSql(data);
- }
- },
- {
- data: "jobIds", name: "jobIds", title: "Succeeded Jobs",
- orderable: false,
- render: function (data, type) {
- if (type !== "display") return (data || []).join(",");
- return jobIdLinks(data || []);
- }
- },
- {
- data: "errorMessage", name: "errorMessage", title: "Error Message",
- orderable: false,
- render: function (data, type) {
- if (type !== "display" || !data) return data || "";
- if (data.length > 100) {
- return '<span title="' + escapeHtml(data) + '">' +
- escapeHtml(data.substring(0, 100)) + '...</span>';
- }
- return escapeHtml(data);
- }
- }
- ],
+ columns: columns,
order: [[0, "desc"]],
language: { search: "Search: " }
});
+ // Child-row expansion for sub-executions. Sub data is embedded per root
row
+ // in the server payload (`row.subExecutions`), so no second fetch is
needed.
+ // Under serverSide: true DataTables destroys/recreates rows on every sort,
+ // filter or page change, so we track expanded row IDs out-of-band and
+ // re-attach the child on each draw.
+ if (groupSubExecEnabled) {
+ var expandedRowIds = {};
+
+ var renderSubExecutionsHtml = function (rowData) {
+ var subs = (rowData && rowData.subExecutions) || [];
+ var basePath = uiRoot + appBasePath;
+ var childId = "sub-exec-" + (rowData && rowData.id);
+ var html = '<table id="' + childId +
+ '" class="table table-sm table-bordered mb-0 sub-exec-table">';
+ html += '<thead><tr><th>ID</th><th>Status</th><th>Description</th>' +
+ '<th>Duration</th><th>Succeeded Jobs</th></tr></thead><tbody>';
+ subs.forEach(function (child) {
+ html += '<tr><td><a href="' + basePath + '/SQL/execution/?id=' +
+ child.id + '">' + child.id + '</a></td>';
+ html += '<td>' + statusBadge(child.status) + '</td>';
+ html += '<td>' + descriptionHtml({
+ id: child.id, description: child.description || ""
+ }) + '</td>';
+ html += '<td>' + formatDurationSql(child.duration) + '</td>';
+ html += '<td>' + jobIdLinks(child.jobIds || []) + '</td></tr>';
+ });
+ html += '</tbody></table>';
+ return html;
+ };
+
+ $("#sql-table tbody").on("click", "a.toggle-sub-exec", function (e) {
+ e.preventDefault();
+ var tr = $(this).closest("tr");
+ var dtRow = table.row(tr);
+ var rowData = dtRow.data();
+ var subs = (rowData && rowData.subExecutions) || [];
+ if (dtRow.child.isShown()) {
+ dtRow.child.hide();
+ tr.removeClass("shown");
+ $(this).text("+" + subs.length + " sub").attr("aria-expanded",
"false");
+ delete expandedRowIds[rowData.id];
+ } else {
+ dtRow.child(renderSubExecutionsHtml(rowData)).show();
+ tr.addClass("shown");
+ $(this).text("\u2212" + subs.length + " sub").attr("aria-expanded",
"true");
+ expandedRowIds[rowData.id] = true;
+ }
+ });
+
+ table.on("draw", function () {
+ $("#sql-table tbody > tr").each(function () {
+ var dtRow = table.row(this);
+ var data = dtRow.data();
+ if (data && expandedRowIds[data.id]) {
+ var subs = data.subExecutions || [];
+ dtRow.child(renderSubExecutionsHtml(data)).show();
+ $(this).addClass("shown");
+ $(this).find("a.toggle-sub-exec")
+ .text("\u2212" + subs.length + " sub")
+ .attr("aria-expanded", "true");
+ }
+ });
+ });
+ }
+
$("#status-filter").on("change", function () {
table.draw();
});
diff --git
a/sql/core/src/main/scala/org/apache/spark/status/api/v1/sql/SqlResource.scala
b/sql/core/src/main/scala/org/apache/spark/status/api/v1/sql/SqlResource.scala
index 91d3f9a484e2..59a1264993e1 100644
---
a/sql/core/src/main/scala/org/apache/spark/status/api/v1/sql/SqlResource.scala
+++
b/sql/core/src/main/scala/org/apache/spark/status/api/v1/sql/SqlResource.scala
@@ -19,12 +19,14 @@ package org.apache.spark.status.api.v1.sql
import java.util.{Date, HashMap}
+import scala.jdk.CollectionConverters._
import scala.util.{Failure, Success, Try}
import jakarta.ws.rs._
import jakarta.ws.rs.core.{Context, MediaType, UriInfo}
import org.apache.spark.JobExecutionStatus
+import org.apache.spark.internal.config.UI.UI_SQL_GROUP_SUB_EXECUTION_ENABLED
import org.apache.spark.sql.execution.ui.{SparkPlanGraph,
SparkPlanGraphCluster, SparkPlanGraphNode, SQLAppStatusStore,
SQLExecutionUIData}
import org.apache.spark.status.api.v1.{BaseAppResource, NotFoundException}
import org.apache.spark.ui.UIUtils
@@ -74,6 +76,11 @@ private[v1] class SqlResource extends BaseAppResource {
* Server-side DataTables endpoint for SQL executions listing.
* Accepts DataTables server-side parameters (start, length, order, search)
* and returns paginated results with recordsTotal/recordsFiltered counts.
+ *
+ * When `groupSubExecution=true` (default =
`spark.ui.groupSQLSubExecutionEnabled`),
+ * pagination is over root executions only and each row carries its
sub-executions
+ * inline as `subExecutions: [...]`. Sub-executions whose root is missing
from the
+ * filtered set (orphans) are surfaced as roots so they don't disappear.
*/
@GET
@Path("sqlTable")
@@ -85,7 +92,11 @@ private[v1] class SqlResource extends BaseAppResource {
// Echo draw counter to prevent stale responses
val draw = Option(uriParams.getFirst("draw")).map(_.toInt).getOrElse(0)
- val totalRecords = sqlStore.executionsCount()
+ // Sub-execution grouping flag; default to the cluster config. Defensive
+ // parse - bad values should not 500 the public REST endpoint.
+ val groupSubExec = Option(uriParams.getFirst("groupSubExecution"))
+ .flatMap(v => Try(v.toBoolean).toOption)
+ .getOrElse(ui.conf.get(UI_SQL_GROUP_SUB_EXECUTION_ENABLED))
// Search and status filter
val searchValue = Option(uriParams.getFirst("search[value]"))
@@ -94,9 +105,14 @@ private[v1] class SqlResource extends BaseAppResource {
.filter(_.nonEmpty)
val needsFilter = searchValue.isDefined || statusFilter.isDefined
+ // Always load all execs once. We need the full set to (a) identify
orphan
+ // sub-executions whose root is filtered out and (b) count root rows for
+ // `recordsTotal`. `sqlStore.executionsList()` is already a full
+ // materialization, so there is no separate "KVStore-pagination" path
being
+ // disabled here.
+ val allExecs = sqlStore.executionsList()
+
val filteredExecs = if (needsFilter) {
- // When filtering, we must load all and filter in memory
- val allExecs = sqlStore.executionsList()
allExecs.filter { exec =>
val matchesSearch = searchValue.forall { search =>
val lower = search.toLowerCase(java.util.Locale.ROOT)
@@ -110,10 +126,14 @@ private[v1] class SqlResource extends BaseAppResource {
matchesSearch && matchesStatus
}
} else {
- // No filter — will use KVStore pagination below
- Seq.empty
+ allExecs
+ }
+
+ val (rootRows, subsByRoot) = if (groupSubExec) {
+ SqlResource.partitionRoots(filteredExecs)
+ } else {
+ (filteredExecs, Map.empty[Long, Seq[SQLExecutionUIData]])
}
- val filteredRecords = if (needsFilter) filteredExecs.size else
totalRecords
// Sort
val sortCol = Option(uriParams.getFirst("order[0][column]"))
@@ -125,26 +145,43 @@ private[v1] class SqlResource extends BaseAppResource {
val start = Option(uriParams.getFirst("start")).map(_.toInt).getOrElse(0)
val length =
Option(uriParams.getFirst("length")).map(_.toInt).getOrElse(20)
- val page = if (needsFilter) {
- // Filter/search: sort and paginate in memory
- val sorted = sortExecs(filteredExecs, sortCol, sortDir)
- if (length > 0) sorted.slice(start, start + length) else sorted
- } else {
- // No filter: use KVStore-level pagination for efficiency
- // KVStore returns in insertion order; sort in memory for the page
- val execs = sqlStore.executionsList()
- val sorted = sortExecs(execs, sortCol, sortDir)
- if (length > 0) sorted.slice(start, start + length) else sorted
+ val sortedRoots = sortExecs(rootRows, sortCol, sortDir)
+ val page = if (length > 0) sortedRoots.slice(start, start + length) else
sortedRoots
+
+ // Convert to Java-compatible row data; embed sub-executions when
grouping.
+ // Always emit a `subExecutions` field (possibly empty) in grouped mode
so
+ // JSON consumers see a consistent schema; flat mode never includes it.
+ val aaData = page.map { exec =>
+ val row = execToRow(exec)
+ if (groupSubExec) {
+ val subs = subsByRoot.getOrElse(exec.executionId, Seq.empty)
+ // Sort subs by id ascending so they appear in chronological order
+ row.put("subExecutions", sortExecs(subs, "id",
"asc").map(execToRow).asJava)
+ }
+ row
}
- // Convert to Java-compatible row data
- val aaData = page.map(execToRow)
+ // Counts: grouped totals reflect root-only counts so DataTables shows
+ // "Showing X to Y of Z entries" matching the rows the user actually
sees.
+ // Flat mode's recordsTotal is the unfiltered total (from the KVStore),
+ // which lets DataTables show the "filtered from W total entries" suffix.
+ val recordsTotal = if (groupSubExec) {
+ if (needsFilter) {
+ // Re-derive root rows from the unfiltered set using the same
predicate
+ SqlResource.partitionRoots(allExecs)._1.size
+ } else {
+ rootRows.size
+ }
+ } else {
+ sqlStore.executionsCount()
+ }
+ val recordsFiltered = if (groupSubExec) rootRows.size else
filteredExecs.size
val ret = new HashMap[String, Object]()
ret.put("draw", Integer.valueOf(draw))
ret.put("aaData", aaData)
- ret.put("recordsTotal", java.lang.Long.valueOf(filteredRecords))
- ret.put("recordsFiltered", java.lang.Long.valueOf(filteredRecords))
+ ret.put("recordsTotal", java.lang.Long.valueOf(recordsTotal))
+ ret.put("recordsFiltered", java.lang.Long.valueOf(recordsFiltered))
ret
}
}
@@ -275,3 +312,22 @@ private[v1] class SqlResource extends BaseAppResource {
}
}
+
+private[v1] object SqlResource {
+
+ /**
+ * Split a set of executions into root rows and a sub-execution map. A root
row is
+ * either an execution whose id equals its rootExecutionId, or an orphan sub
whose
+ * root parent is absent from the input set. Called on the filtered set (for
paging)
+ * and on the full set (for `recordsTotal`), so the predicate lives in one
place
+ * rather than being inlined twice.
+ */
+ def partitionRoots(execs: Seq[SQLExecutionUIData])
+ : (Seq[SQLExecutionUIData], Map[Long, Seq[SQLExecutionUIData]]) = {
+ val ids = execs.iterator.map(_.executionId).toSet
+ val (roots, subs) = execs.partition { e =>
+ e.executionId == e.rootExecutionId || !ids.contains(e.rootExecutionId)
+ }
+ (roots, subs.groupBy(_.rootExecutionId))
+ }
+}
diff --git
a/sql/core/src/test/scala/org/apache/spark/status/api/v1/sql/SqlResourceWithActualMetricsSuite.scala
b/sql/core/src/test/scala/org/apache/spark/status/api/v1/sql/SqlResourceWithActualMetricsSuite.scala
index 6cae4fb30668..f03aff39b532 100644
---
a/sql/core/src/test/scala/org/apache/spark/status/api/v1/sql/SqlResourceWithActualMetricsSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/status/api/v1/sql/SqlResourceWithActualMetricsSuite.scala
@@ -31,6 +31,7 @@ import
org.apache.spark.deploy.history.HistoryServerSuite.getContentAndCode
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.catalyst.analysis.TableAlreadyExistsException
import org.apache.spark.sql.execution.metric.SQLMetricsTestUtils
+import org.apache.spark.sql.execution.ui.SQLExecutionUIData
import org.apache.spark.sql.internal.SQLConf.ADAPTIVE_EXECUTION_ENABLED
import org.apache.spark.sql.test.SharedSparkSession
@@ -215,6 +216,119 @@ class SqlResourceWithActualMetricsSuite
}
}
+ test("SPARK-56811: sqlTable groups sub-executions under their root
execution") {
+ // CACHE TABLE produces a root execution plus an inner sub-execution that
+ // shares its rootExecutionId. This is the canonical case where the SQL
+ // listing should fold the sub row under the root rather than flattening
it.
+ spark.sql("CREATE OR REPLACE TEMP VIEW spark_56811 AS SELECT id FROM
RANGE(10)")
+ .collect()
+ spark.sql("CACHE TABLE spark_56811_cached AS SELECT * FROM
spark_56811").collect()
+ try {
+ eventually(timeout(10.seconds), interval(1.second)) {
+ val baseUrl = spark.sparkContext.ui.get.webUrl +
+
s"/api/v1/applications/${spark.sparkContext.applicationId}/sql/sqlTable"
+
+ // Grouping ON: roots only, with subExecutions embedded on the root
that
+ // owns a sub-execution.
+ val groupedUrl = new URI(
+ s"$baseUrl?start=0&length=100&draw=1&groupSubExecution=true").toURL
+ val (groupedCode, groupedOpt, _) = getContentAndCode(groupedUrl)
+ assert(groupedCode === HttpServletResponse.SC_OK)
+ val groupedJson = JsonMethods.parse(groupedOpt.get)
+ val groupedRecordsTotal = (groupedJson \ "recordsTotal").extract[Long]
+ val groupedRecordsFiltered = (groupedJson \
"recordsFiltered").extract[Long]
+ val groupedRows = (groupedJson \ "aaData").children
+ assert(groupedRecordsTotal === groupedRows.size,
+ "with no filter, recordsTotal should match returned root count")
+ assert(groupedRecordsFiltered === groupedRows.size,
+ "with no filter, recordsFiltered should match returned root count")
+ // Every row in grouped mode is either a true root (id ==
rootExecutionId)
+ // or an orphan sub whose real parent is absent from the result set.
+ val visibleIds = groupedRows.map(r => (r \ "id").extract[Long]).toSet
+ groupedRows.foreach { row =>
+ val id = (row \ "id").extract[Long]
+ val rootId = (row \ "rootExecutionId").extract[Long]
+ assert(id == rootId || !visibleIds.contains(rootId),
+ s"grouped row $id (rootId=$rootId) is neither a root nor an
orphan")
+ }
+ val rootsWithSubs = groupedRows.filter { row =>
+ (row \ "subExecutions").children.nonEmpty
+ }
+ assert(rootsWithSubs.nonEmpty,
+ "CACHE TABLE should produce at least one root with sub-executions")
+ rootsWithSubs.foreach { row =>
+ val rootId = (row \ "id").extract[Long]
+ (row \ "subExecutions").children.foreach { sub =>
+ assert((sub \ "rootExecutionId").extract[Long] === rootId,
+ "sub-execution should reference its parent root")
+ assert((sub \ "id").extract[Long] !== rootId,
+ "sub-execution must not have the same id as its root")
+ }
+ }
+
+ // Grouping OFF: flat list of every execution, with no embedded subs.
+ val flatUrl = new URI(
+ s"$baseUrl?start=0&length=100&draw=2&groupSubExecution=false").toURL
+ val (flatCode, flatOpt, _) = getContentAndCode(flatUrl)
+ assert(flatCode === HttpServletResponse.SC_OK)
+ val flatJson = JsonMethods.parse(flatOpt.get)
+ val flatRows = (flatJson \ "aaData").children
+ assert(flatRows.size > groupedRows.size,
+ "flat listing should contain at least one extra sub-execution row")
+ val embeddedSubs = groupedRows.map(r => (r \
"subExecutions").children.size).sum
+ assert(flatRows.size === groupedRows.size + embeddedSubs,
+ "flat size should equal grouped roots plus embedded sub rows")
+ flatRows.foreach { row =>
+ assert((row \ "subExecutions").children.isEmpty,
+ "flat listing should not embed subExecutions")
+ }
+ }
+ } finally {
+ spark.sql("UNCACHE TABLE IF EXISTS spark_56811_cached")
+ }
+ }
+
+ test("SPARK-56811: partitionRoots surfaces orphan sub-executions as root
rows") {
+ def mkExec(id: Long, rootId: Long): SQLExecutionUIData = new
SQLExecutionUIData(
+ executionId = id,
+ rootExecutionId = rootId,
+ description = s"exec $id",
+ details = "",
+ physicalPlanDescription = "",
+ modifiedConfigs = Map.empty,
+ metrics = Seq.empty,
+ submissionTime = id,
+ completionTime = None,
+ errorMessage = None,
+ jobs = Map.empty,
+ stages = Set.empty,
+ metricValues = null,
+ queryId = null)
+
+ // Tree:
+ // 1 (root) -> 2, 3 (subs)
+ // 4 (root, no subs)
+ // 6 (sub of 5, but 5 is missing -> orphan)
+ val root1 = mkExec(1, 1)
+ val sub2 = mkExec(2, 1)
+ val sub3 = mkExec(3, 1)
+ val root4 = mkExec(4, 4)
+ val orphan6 = mkExec(6, 5)
+
+ val (roots, subsByRoot) =
+ SqlResource.partitionRoots(Seq(root1, sub2, sub3, root4, orphan6))
+
+ assert(roots.map(_.executionId).toSet === Set(1L, 4L, 6L),
+ "true roots and orphan subs should both be promoted to root rows")
+ assert(subsByRoot.keySet === Set(1L),
+ "only execs with a parent present in the input should appear in
subsByRoot")
+ assert(subsByRoot(1L).map(_.executionId).toSet === Set(2L, 3L),
+ "subs should be grouped under their parent root id")
+ val orphanRow = roots.find(_.executionId == 6L).get
+ assert(orphanRow.rootExecutionId === 5L,
+ "orphan promoted to a root row preserves its original rootExecutionId")
+ }
+
test("SPARK-56137: sqlList returns ISO date format in submissionTime") {
withSQLConf(ADAPTIVE_EXECUTION_ENABLED.key -> "false") {
spark.sql("SELECT 'date_format_test'").collect()
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}