This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8704f6bcaf1 [SPARK-43214][SQL] Post driver-side metrics for
LocalTableScanExec/CommandResultExec
8704f6bcaf1 is described below
commit 8704f6bcaf135247348599119723bb2cd84f6c63
Author: Fu Chen <[email protected]>
AuthorDate: Mon Apr 24 18:48:04 2023 +0800
[SPARK-43214][SQL] Post driver-side metrics for
LocalTableScanExec/CommandResultExec
### What changes were proposed in this pull request?
Since `LocalTableScan`/`CommandResultExec` may not trigger a Spark job,
post the driver-side metrics even in scenarios where a Spark job is not
triggered, so that we can track the metrics in the SQL UI tab.
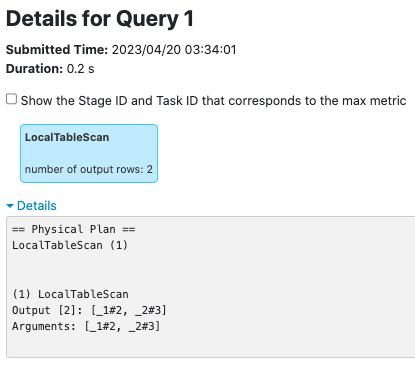
**LocalTableScanExec**
before this PR:
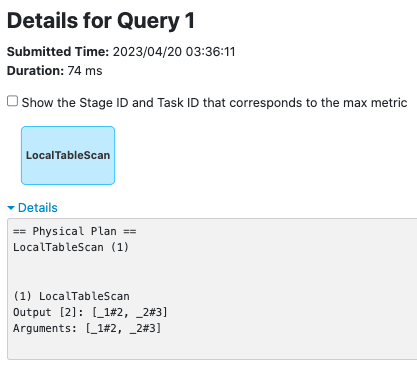
after this PR:
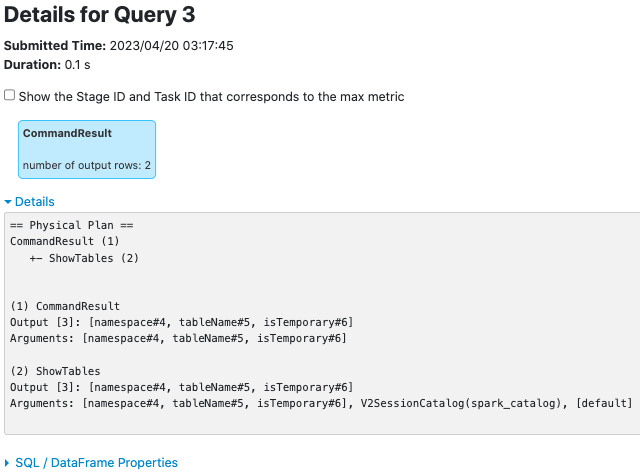
**CommandResultExec**
before this PR:
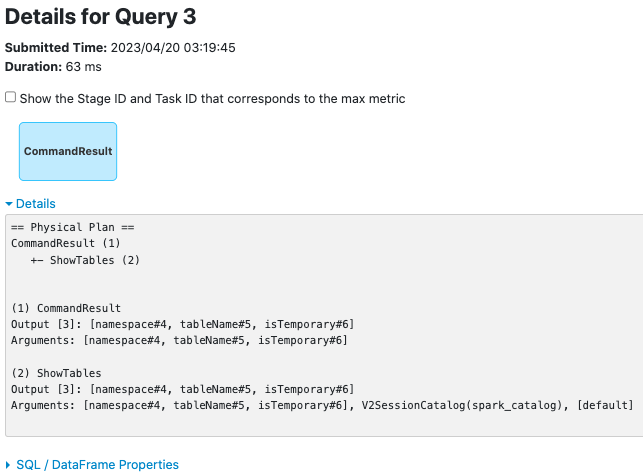
after this PR:
### Why are the changes needed?
makes metrics of `LocalTableScanExec`/`CommandResultExec` trackable on the
SQL UI tab
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
new UT.
Closes #40875 from cfmcgrady/SPARK-43214.
Authored-by: Fu Chen <[email protected]>
Signed-off-by: Wenchen Fan <[email protected]>
---
.../spark/sql/execution/CommandResultExec.scala | 8 +++++++
.../spark/sql/execution/LocalTableScanExec.scala | 8 +++++++
.../sql/execution/metric/SQLMetricsSuite.scala | 27 ++++++++++++++++++++++
3 files changed, 43 insertions(+)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
index 21d1c97db98..5f38278d2dc 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
@@ -77,18 +77,21 @@ case class CommandResultExec(
override def executeCollect(): Array[InternalRow] = {
longMetric("numOutputRows").add(unsafeRows.size)
+ sendDriverMetrics()
unsafeRows
}
override def executeTake(limit: Int): Array[InternalRow] = {
val taken = unsafeRows.take(limit)
longMetric("numOutputRows").add(taken.size)
+ sendDriverMetrics()
taken
}
override def executeTail(limit: Int): Array[InternalRow] = {
val taken: Seq[InternalRow] = unsafeRows.takeRight(limit)
longMetric("numOutputRows").add(taken.size)
+ sendDriverMetrics()
taken.toArray
}
@@ -96,4 +99,9 @@ case class CommandResultExec(
override protected val createUnsafeProjection: Boolean = false
override def inputRDD: RDD[InternalRow] = rdd
+
+ private def sendDriverMetrics(): Unit = {
+ val executionId =
sparkContext.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+ SQLMetrics.postDriverMetricUpdates(sparkContext, executionId,
metrics.values.toSeq)
+ }
}
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
index 1a79c08dabd..f178cd63dfe 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
@@ -73,18 +73,21 @@ case class LocalTableScanExec(
override def executeCollect(): Array[InternalRow] = {
longMetric("numOutputRows").add(unsafeRows.size)
+ sendDriverMetrics()
unsafeRows
}
override def executeTake(limit: Int): Array[InternalRow] = {
val taken = unsafeRows.take(limit)
longMetric("numOutputRows").add(taken.size)
+ sendDriverMetrics()
taken
}
override def executeTail(limit: Int): Array[InternalRow] = {
val taken: Seq[InternalRow] = unsafeRows.takeRight(limit)
longMetric("numOutputRows").add(taken.size)
+ sendDriverMetrics()
taken.toArray
}
@@ -92,4 +95,9 @@ case class LocalTableScanExec(
override protected val createUnsafeProjection: Boolean = false
override def inputRDD: RDD[InternalRow] = rdd
+
+ private def sendDriverMetrics(): Unit = {
+ val executionId =
sparkContext.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+ SQLMetrics.postDriverMetricUpdates(sparkContext, executionId,
metrics.values.toSeq)
+ }
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/metric/SQLMetricsSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/metric/SQLMetricsSuite.scala
index ff477fb16b7..877e2cadcfb 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/metric/SQLMetricsSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/metric/SQLMetricsSuite.scala
@@ -80,6 +80,33 @@ class SQLMetricsSuite extends SharedSparkSession with
SQLMetricsTestUtils
assert(metrics2("numOutputRows").value === 2)
}
+ test("SPARK-43214: LocalTableScanExec metrics") {
+ val df1 = spark.createDataset(Seq(1, 2, 3))
+ val logical = df1.queryExecution.logical
+ require(logical.isInstanceOf[LocalRelation])
+ df1.collect()
+
+ val expected = Map("number of output rows" -> 3L)
+ testSparkPlanMetrics(df1.toDF(), 0, Map(
+ 0L -> (("LocalTableScan", expected))))
+ }
+
+ test("SPARK-43214: CommandResultExec metrics") {
+ withTable("t", "t2") {
+ sql("CREATE TABLE t(id STRING) USING PARQUET")
+ sql("CREATE TABLE t2(id STRING) USING PARQUET")
+ val df = sql("SHOW TABLES")
+ val command = df.queryExecution.executedPlan.collect {
+ case cmd: CommandResultExec => cmd
+ }
+ sparkContext.listenerBus.waitUntilEmpty()
+ assert(command.size == 1)
+ val expected = Map("number of output rows" -> 2L)
+ testSparkPlanMetrics(df, 0, Map(
+ 0L -> (("CommandResult", expected))))
+ }
+ }
+
test("Filter metrics") {
// Assume the execution plan is
// PhysicalRDD(nodeId = 1) -> Filter(nodeId = 0)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}