Mark Adams <mfad...@lbl.gov> writes: > I've have a test up and running but hypre and GAMG are running very very > slow. The test only has about 100 equation per core. Jed mentioned 20K > cycles to start OMP parallel (really?) which would explain a lot. Do I > understand that correctly Jed?
Yes, >20k cycles on KNC is what John McCalpin reports [1]. Somewhat
less on more reasonable architectures like Xeon (which also has a faster
clock rate), but still huge. Cycle counts for my attached test code:
cg.mcs.anl.gov (4x Opteron 6274 @ 2.2 GHz), ICC 13.1.3
$ make -B CC=icc CFLAGS='-std=c99 -fopenmp -fast' omp-test
icc -std=c99 -fopenmp -fast omp-test.c -o omp-test
$ for n in 1 2 4 8 12 16 24 32 48 64; do ./omp-test $n 10000 10 16; done
1 threads, 64 B: Min 647 Max 2611 Avg 649
2 threads, 128 B: Min 6817 Max 12689 Avg 7400
4 threads, 256 B: Min 7602 Max 15105 Avg 8910
8 threads, 512 B: Min 10408 Max 21640 Avg 11769
12 threads, 768 B: Min 13588 Max 22176 Avg 15608
16 threads, 1024 B: Min 15748 Max 26853 Avg 17397
24 threads, 1536 B: Min 19503 Max 32095 Avg 22130
32 threads, 2048 B: Min 21213 Max 36480 Avg 23688
48 threads, 3072 B: Min 25306 Max 613552 Avg 29799
64 threads, 4096 B: Min 106807 Max 47592474 Avg 291975
(The largest size may not be representative because someone's
8-process job was running. The machine was otherwise idle.)
For comparison, we can execute in serial with the same buffer sizes:
$ for n in 1 2 4 8 12 16 24 32 48 64; do ./omp-test 1 1000 1000 $[16*$n]; done
1 threads, 64 B: Min 645 Max 696 Avg 662
1 threads, 128 B: Min 667 Max 769 Avg 729
1 threads, 256 B: Min 682 Max 718 Avg 686
1 threads, 512 B: Min 770 Max 838 Avg 802
1 threads, 768 B: Min 788 Max 890 Avg 833
1 threads, 1024 B: Min 849 Max 899 Avg 870
1 threads, 1536 B: Min 941 Max 1007 Avg 953
1 threads, 2048 B: Min 1071 Max 1130 Avg 1102
1 threads, 3072 B: Min 1282 Max 1354 Avg 1299
1 threads, 4096 B: Min 1492 Max 1686 Avg 1514
es.mcs.anl.gov (2x E5-2650v2 @ 2.6 GHz), ICC 13.1.3
$ make -B CC=icc CFLAGS='-std=c99 -fopenmp -fast' omp-test
icc -std=c99 -fopenmp -fast omp-test.c -o omp-test
$ for n in 1 2 4 8 12 16 24 32; do ./omp-test $n 10000 10 16; done
1 threads, 64 B: Min 547 Max 19195 Avg 768
2 threads, 128 B: Min 1896 Max 9821 Avg 1966
4 threads, 256 B: Min 4489 Max 23076 Avg 5891
8 threads, 512 B: Min 6954 Max 24801 Avg 7784
12 threads, 768 B: Min 7146 Max 23007 Avg 7946
16 threads, 1024 B: Min 8296 Max 30338 Avg 9427
24 threads, 1536 B: Min 8930 Max 14236 Avg 9815
32 threads, 2048 B: Min 47937 Max 38485441 Avg 54358
(This machine was idle.)
And the serial comparison:
$ for n in 1 2 4 8 12 16 24 32; do ./omp-test 1 1000 1000 $[16*$n]; done
1 threads, 64 B: Min 406 Max 1293 Avg 500
1 threads, 128 B: Min 418 Max 557 Avg 427
1 threads, 256 B: Min 428 Max 589 Avg 438
1 threads, 512 B: Min 469 Max 641 Avg 471
1 threads, 768 B: Min 505 Max 631 Avg 508
1 threads, 1024 B: Min 536 Max 733 Avg 538
1 threads, 1536 B: Min 588 Max 813 Avg 605
1 threads, 2048 B: Min 627 Max 809 Avg 630
So we're talking about 3 µs (Xeon) to 10 µs (Opteron) overhead for omp
parallel even with these small numbers of cores. This is more than
ping-pong round trip on decent networks and 20 µs (one to pack, one to
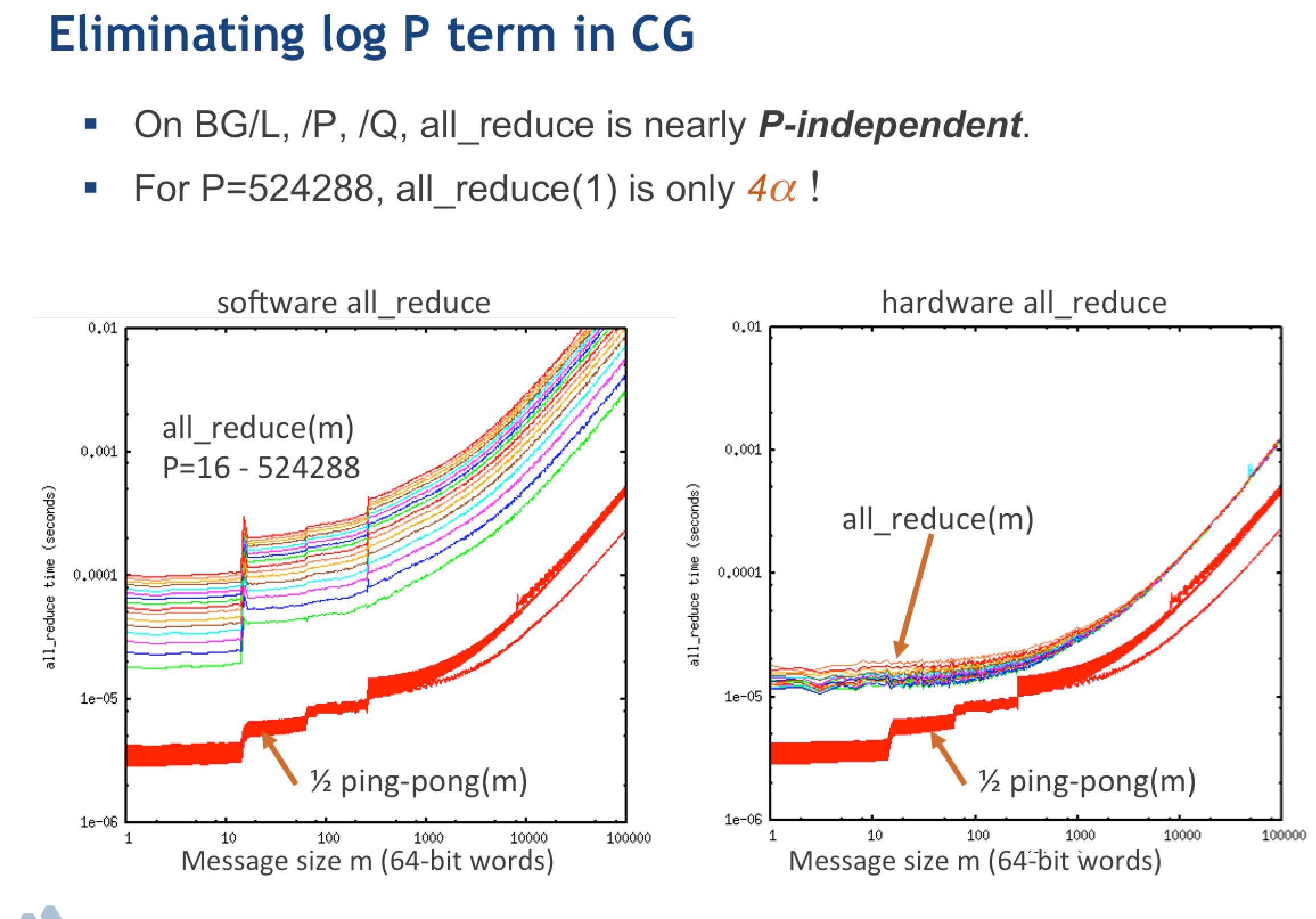
unpack on the Opteron) is more than the cost of MPI_Allreduce on a
million cores of BG/Q [2]. You're welcome to run it for yourself on
Titan or wherever else.
The simple conclusion is that putting omp parallel in the critical path
is a terrible plan for strong scaling and downright silly if you're
spending money on a low-latency network.
[1] https://software.intel.com/en-us/forums/topic/537436#comment-1808790
[2] http://www.mcs.anl.gov/~fischer/bgq_all_reduce.png
{kind=link}
#define _POSIX_C_SOURCE 199309L
#include <stdio.h>
#include <omp.h>
#include <stdlib.h>
typedef unsigned long long cycles_t;
cycles_t rdtsc() {
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ((cycles_t)lo)|( ((cycles_t)hi)<<32);
}
int main(int argc,char *argv[]) {
if (argc != 5) {
fprintf(stderr,"Usage: %s NUM_THREADS NUM_SAMPLES SAMPLE_ITERATIONS LOCAL_SIZE\n",argv[0]);
return 1;
}
int nthreads = atoi(argv[1]),num_samples = atoi(argv[2]),sample_its = atoi(argv[3]),lsize = atoi(argv[4]);
omp_set_num_threads(nthreads);
int *buf = calloc(nthreads*lsize,sizeof(int));
// Warm up the thread pools
#pragma omp parallel for
for (int k=0; k<nthreads*lsize; k++) buf[k]++;
cycles_t max=0,min=1e10,sum=0;
for (int i=0; i<num_samples; i++) {
cycles_t t = rdtsc();
for (int j=0; j<sample_its; j++) {
#pragma omp parallel for
for (int k=0; k<nthreads*lsize; k++) buf[k]++;
}
t = (rdtsc() - t)/sample_its;
if (t > max) max = t;
if (t < min) min = t;
sum += t;
}
printf("% 3d threads, %4zd B: Min %8llu Max %8llu Avg %8llu\n",nthreads,nthreads*lsize*sizeof(int),min,max,sum/num_samples);
return 0;
}
![]() signature.asc
signature.asc
Description: PGP signature